项目:遗传
TIP
我们为你提供了一个简单有趣的项目,帮助你进行知识巩固,请认真阅读文档内容。
如果你卡住了,请记得回来阅读文档,或请求身边人的帮助。
📥
本节附件下载
背景
GJB2 基因的突变版本是导致新生儿听力障碍的主要原因之一。每个人都携带两个版本的基因,因此每个人都有可能拥有 0、1 或 2 个听力障碍版本的 GJB2 基因。不过,除非一个人接受基因测试,否则要知道一个人拥有多少个变异的 GJB2 基因并不那么容易。这是一些 "隐藏状态":具有我们可以观察到的影响(听力损伤)的信息,但我们不一定直接知道。毕竟,有些人可能有 1 或 2 个突变的 GJB2 基因,但没有表现出听力障碍,而其他人可能没有突变的 GJB2 基因,但仍然表现出听力障碍。
每个孩子都会从他们的父母那里继承一个 GJB2 基因。如果父母有两个变异基因,那么他们会将变异基因传给孩子;如果父母没有变异基因,那么他们不会将变异基因传给孩子;如果父母有一个变异基因,那么该基因传给孩子的概率为 0.5。不过,在基因被传递后,它有一定的概率发生额外的突变:从导致听力障碍的基因版本转变为不导致听力障碍的版本,或者反过来。
我们可以尝试通过对所有相关变量形成一个贝叶斯网络来模拟所有这些关系,就像下面这个网络一样,它考虑了一个由两个父母和一个孩子组成的家庭。
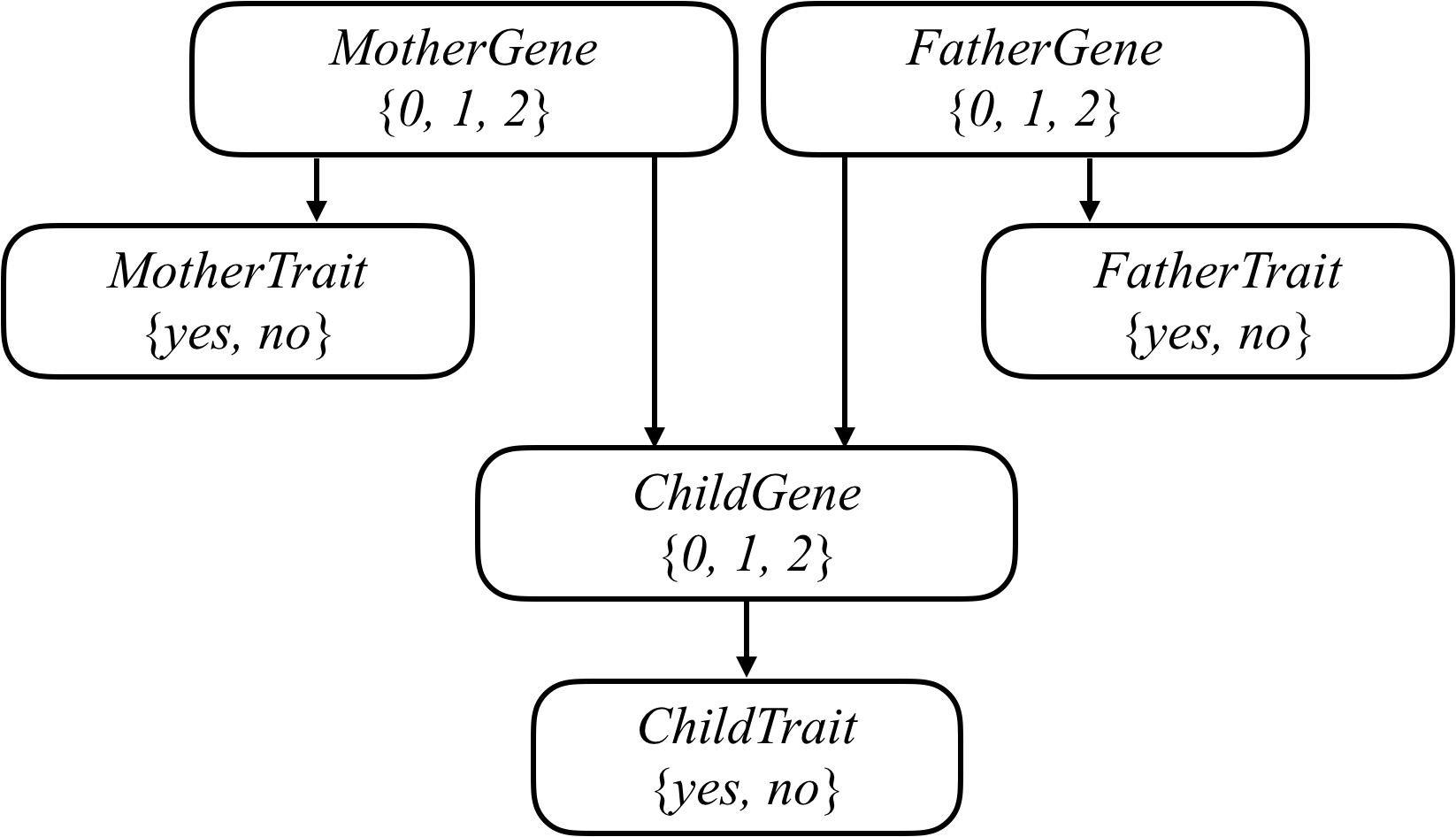
家庭中的每个人都有一个 Gene 随机变量,代表一个人有多少个特定基因(例如,GJB2 的听力障碍版本):一个 0、1 或 2 的值。家族中的每个人也有一个 Trait 随机变量,它是 yes 或 no ,取决于该人是否表达基于该基因的性状(例如,听力障碍)。从每个人的 Gene 变量到他们的 Trait 变量之间有一个箭头,以编码一个人的基因影响他们具有特定性状的概率的想法。同时,也有一个箭头从母亲和父亲的 Gene 随机变量到他们孩子的 Gene 随机变量:孩子的基因取决于他们父母的基因。
你在这个项目中的任务是使用这个模型对人群进行推断。给出人们的信息,他们的父母是谁,以及他们是否具有由特定基因引起的特定可观察特征(如听力损失),你的人工智能将推断出每个人的基因的概率分布,以及任何一个人是否会表现出有关特征的概率分布。
理解
打开 data/family0.csv ,看看数据目录中的一个样本数据集(你可以在文本编辑器中打开,或者在 Google Sheets、Excel 或 Apple Numbers 等电子表格应用程序中打开)。注意,第一行定义了这个 CSV 文件的列: name , mother , father , 和 trait 。下一行表明 Harry 的母亲是 Lily,父亲是 James,而 Trait 的空单元格意味着我们不知道 Harry 是否有这种性状。同时,James 在我们的数据集中没有列出父母(如母亲和父亲的空单元格所示),但确实表现出了性状(如 Trait 单元格中的 1 所示)。另一方面,Lily 在数据集中也没有列出父母,但没有表现出这种性状(如 Trait 单元格中的 0 表示)。
打开 heredity.py ,首先看一下 PROBS 的定义。 PROBS 是一个包含若干常数的字典,代表各种不同事件的概率。所有这些事件都与一个人拥有多少个特定的突变基因,以及一个人是否基于该基因表现出特定的性状有关。这里的数据松散地基于 GJB2 基因的听力障碍版本和听力障碍性状的概率,但通过改变这些值,你也可以用你的人工智能来推断其他的基因和性状!
首先, PROBS["gene"] 代表了该基因的无条件概率分布(即如果我们对该人的父母一无所知的概率)。根据分布代码中的数据,在人群中,有 1% 的机会拥有该基因的 2 个副本,3% 的机会拥有该基因的 1 个副本,96% 的机会拥有该基因的零副本。
接下来, PROBS["trait"] 表示一个人表现出某种性状(如听力障碍)的条件概率。这实际上是三个不同的概率分布:基因的每个可能值都有一个。因此, PROBS["trait"][2] 是一个人在有两个突变基因的情况下具有该特征的概率分布:在这种情况下,他们有 65% 的机会表现出该特征,而有 35% 的机会不表现出该特征。同时,如果一个人有 0 个变异基因,他们有 1% 的机会表现出该性状,99% 的机会不表现出该性状。
最后, PROBS["mutation"] 是一个基因从作为相关基因突变为不是该基因的概率,反之亦然。例如,如果一个母亲有两个变异基因,并因此将其中一个传给她的孩子,就有 1% 的机会突变为不再是变异基因。相反,如果一个母亲没有任何变异基因,因此没有把变异基因传给她的孩子,但仍有 1% 的机会突变为变异基因。因此,即使父母双方都没有变异基因,他们的孩子也可能有 1 个甚至 2 个变异基因。
最终,你计算的概率将以 PROBS 中的这些数值为基础。
现在,看一下 main 函数。该函数首先将数据从一个文件加载到一个字典 people 中。 people 将每个人的名字映射到另一个包含他们信息的字典中:包括他们的名字,他们的母亲(如果数据集中有一个母亲),他们的父亲(如果数据集中有一个父亲),以及他们是否被观察到有相关的特征(如果有则为 True ,没有则为 False ,如果我们不知道则为 None )。 接下来, main 中定义了一个字典 probabilities ,所有的概率最初都设置为 0。这就是你的项目最终要计算的内容:对于每个人,你的人工智能将计算他们有多少个变异基因的概率分布,以及他们是否具有该性状。例如, probabilities["Harry"]["gene"][1] 将是 Harry 有 1 个变异基因的概率,而 probabilities["Lily"]["trait"][False] 将是 Lily 没有表现出该性状的概率。
如果不熟悉的话,这个 probabilities 字典是用 python 字典创建的,在这种情况下,它为我们的 people 中的每个 person 创建一个键 / 值对。
最终,我们希望根据一些证据来计算这些概率:鉴于我们知道某些人有或没有这种特征,我们想确定这些概率。你在这个项目中的任务是实现三个函数来做到这一点: joint_probability 计算一个联合概率, update 将新计算的联合概率添加到现有的概率分布中,然后 normalize 以确保所有概率分布最后和为 1。
明确
完成 joint_probability 、 update 和 normalize 的实现。
joint_probability 函数应该接受一个 people 的字典作为输入,以及关于谁拥有多少个变异基因,以及谁表现出该特征的数据。该函数应该返回所有这些事件发生的联合概率。
该函数接受四个数值作为输入:
people,one_gene,two_genes, 和have_trait。people是一个在 "理解" 一节中描述的人的字典。键代表名字,值是包含mother和father键的字典。你可以假设mother和father都是空白的(数据集中没有父母的信息),或者mother和father都会指代people字典中的其他人物。one_gene是一个集合,我们想计算所有集合元素有一个变异基因的概率。two_genes是一个集合,我们想计算所有集合元素有两个变异基因的概率。have_trait是一个集合,我们想计算所有集合元素拥有该性状的概率。- 对于不在
one_gene或 two_genes中的人,我们想计算他们没有变异基因的概率;对于不在have_trait中的人,我们想计算他们没有该性状的概率。
例如,如果这个家庭由 Harry、James 和 Lily 组成,那么在
one_gene = {"Harry"}、two_genes = {"James"}和trait = {"Harry"、"James"}的情况下调用这个函数,应该计算出 Lily 没有变异基因、Harry 拥有一个变异基因、James 拥有两个变异基因、Harry 表现出该性状、James 表现出该性状和 Lily 没有表现出该性状的联合概率。对于数据集中没有列出父母的人,使用概率分布
PROBS["gene"]来确定他们有特定数量基因的概率。对于数据集中有父母的人来说,每个父母都会把他们的两个基因中的一个随机地传给他们的孩子,而且有一个
PROBS["mutation"]的机会,即它会发生突变(从变异基因变成正常基因,或者相反)。使用概率分布
PROBS["trait"]来计算一个人具有或不具有形状的概率。
update 函数将一个新的联合分布概率添加到 probabilities 中的现有概率分布中。
该函数接受五个值作为输入:
probabilities,one_gene,two_genes,have_trait, 和p。probabilities是一个在 "理解" 部分提到的字典。每个人都被映射到一个"gene"分布和一个"trait"分布。one_gene是一个集合,我们想计算所有集合元素有一个变异基因的概率。two_genes是一个集合,我们想计算所有集合元素有两个变异基因的概率。have_trait是一个集合,我们想计算所有集合元素拥有该性状的概率。p是联合分布的概率。
对于概率中的每个人,该函数应该更新
probabilities[person]["gene"]分布和probabilities[person]["trait"]分布,在每个分布中的适当数值上加上p。所有其他数值应保持不变。例如,如果 "Harry" 同时出现在
two_genes和have_trait中,那么p将被添加到probabilities["Harry"]["gene"][2]和probabilities["Harry"]["trait"][True]。该函数不应返回任何值:它只需要更新
probabilities字典。
normalize 函数更新 probabilities 字典,使每个概率分布被归一化(即和为 1,相对比例相同)。
该函数接受一个单一的值:
probabilities。probabilities是一个在 "理解" 部分提到的字典。每个人都被映射到一个"gene"分布和一个"trait"分布。
对于
probabilities中每个人的两个分布,这个函数应该将该分布归一化,使分布中的数值之和为 1,分布中的相对数值是相同的。例如,如果
probabilities["Harry"]["trait"][True]等于0.1,概率probabilities["Harry"]["trait"][False]等于0.3,那么你的函数应该将前一个值更新为0.25,后一个值更新为0.75: 现在数字之和为 1,而且后一个值仍然比前一个值大三倍。该函数不应返回任何值:它只需要更新
probabilities字典。
除了规范中要求你实现的三个函数外,你不应该修改 heredity.py 中的任何其他东西,尽管你可以编写额外的函数和 / 或导入其他 Python 标准库模块。如果熟悉的话,你也可以导入 numpy 或 pandas ,但是你不应该使用任何其他第三方 Python 模块。
一个联合概率例子
为了帮助你思考如何计算联合概率,我们在下面附上一个例子。
请考虑以下 people 的值:
{
'Harry': {'name': 'Harry', 'mother': 'Lily', 'father': 'James', 'trait': None},
'James': {'name': 'James', 'mother': None, 'father': None, 'trait': True},
'Lily': {'name': 'Lily', 'mother': None, 'father': None, 'trait': False}
}这里我们将展示 joint_probability(people, {"Harry"}, {"James"}, {"James"}) 的计算。根据参数, one_gene 是 {"Harry"} , two_genes 是 {"James"} ,而 has_trait 是 {"James"} 。因此,这代表了以下的概率:Lily 没有变异基因,不具有该性状;Harry 有一个变异基因,不具有该性状;James 有 2 个变异基因,具有该性状。
我们从 Lily 开始(我们考虑人的顺序并不重要,只要我们把正确的数值乘在一起,因为乘法是可交换的)。Lily 没有变异基因,概率为 0.96 (这就是 PROBS["gene"][0] )。鉴于她没有变异基因,她没有这个性状的概率为 0.99 (这是 PROBS["trait"][0][False] )。因此,她没有变异基因且没有该性状的概率是 0.96*0.99=0.9504 。
接下来,我们考虑 James。James 有 2 个变异基因,概率为 0.01 (这是 PROBS["gene"][2] )。鉴于他有 2 个变异基因,他确实具有该性状的概率为 0.65 。因此,他有 2 个变异基因并且他确实具有该性状的概率是 0.01*0.65=0.0065 。
最后,我们考虑 Harry。Harry 有 1 个变异基因的概率是多少?有两种情况可以发生。要么他从母亲那里得到这个基因,而不是从父亲那里,要么他从父亲那里得到这个基因,而不是从母亲那里。他的母亲 Lily 没有变异基因,所以 Harry 会以 0.01 的概率从他母亲那里得到这个基因(这是 PROBS["mutation"] ),因为从他母亲那里得到这个基因的唯一途径是基因突变;相反,Harry 不会从他母亲那里得到这个基因,概率是 0.99 。他的父亲 James 有 2 个变异基因,所以 Harry 会以 0.99 的概率从他父亲那里得到这个基因(这是 1-PROBS["mutation"] ),但会以 0.01 的概率从他母亲那里得到这个基因(突变的概率)。这两种情况加在一起可以得到 0.99*0.99+0.01*0.01=0.9802 ,即 Harry 有 1 个变异基因的概率。
考虑到 Harry 有 1 个变异基因,他没有该性状的概率是 0.44 (这是 PROBS["trait"][1][false] )。因此,哈利有 1 个变异基因而没有该性状的概率是 0.9802 * 0.44 = 0.431288 。
因此,整个联合概率是三个人中每个人的所有这些数值相乘的结果: 0.9504 * 0.0065 * 0.431288 = 0.0026643247488 。
提示
- 回顾一下,要计算多个事件的联合概率,你可以通过将这些概率相乘来实现。但请记住,对于任何孩子来说,他们拥有一定数量的基因的概率是以他们的父母拥有什么基因为条件的。