从 AI 到 智能系统 —— 从 LLMs 到 Agents
author: 廖总
Last revised 2023/04/18
先声夺人:AI 时代最大的陷阱,就是盲目考察 AI 能为我们做什么,而不去考虑我们能为 AI 提供什么
免责声明
本文纯文本量达 16k(我也不知道字数统计的 28k 是怎么来的),在这 游离散乱的主线 和 支离破碎的文字 中挣扎,可能浪费您生命中宝贵的十数分钟。
但如果您坚持尝试阅读,可能看到如下内容(假设没在其中绕晕的话):
- 对大语言模型本质 以及 AI 时代人们生产创作本位 的讨论
- 对大语言模型 上下文学习(In-Context Learning,ICL)和 思维链(Chain of Thought,COT)能力的几种通识性认知
- 围绕 Prompt Decomposition 对使用大语言模型构建复杂应用的基础讨论
- 对当前热门大模型 Agent 化框架(如 Generative Agents(即斯坦福 25 人小镇)、AutoGPT)其本质的讨论
- 对使用大语言模型构建智能系统(基于全局工作空间意识理论)的初步讨论
- 对使用大语言模型构建符合当今生产需求的智能系统的方法论讨论
(顺便,如果这篇的阅读体验有点一路偏题,请不要见怪,因为我也被这两周的新工作一路被带着跑)
(而这也导致了很多从最开始就埋好想说的东西最后懒得挖了,一路开摆)
(所以唯一有参考价值的思路主干就是下面这条总结)
该文章主要分为几个部分:
- 引言:讨论当前基于 AI 构建工程的背景痛点,连带着讨论 AI 智能如何区别于人类,人类仍应在生产中发挥的智能在何处。
- LLMs 能力考察:讨论了大语言模型涌现的一系列基本能力,并讨论基于这些基本能力和工程化,大模型能做到哪一步
- Decomp 方法论:将大语言模型微分化使用的方法论,以此展开对大语言模型的新认知
- AI 作为智能系统:结合 Generative Agents、AutoGPT 两项工作讨论大语言模型本身的局限性,围绕人类认知模型的启发,讨论通过构建复杂系统使得 LLMs Agent 化的可能性
- 予智能以信息:讨论基于 LLMs 构建能够充分帮助我们提升生产力的 AI 剩余的一切痛点。借以回到主题 —— 在 AI 时代,我们要打造什么样的生产和信息管理新范式(有一说,还是空口无凭)
总体而言,本文包括对 LLM 领域近一个月的最新几项工作(TaskMatrix、HuggingGPT、Generative Agents、AutoGPT)的讨论,并基于此考察一个真正可用的 AI 会以什么样的形态出现在我们面前。
而本文的核心观点如下:
- 大语言模型的实质是一个拥有智能计算能力的语言计算器
- 我们不该将其当作独立的智能体看待,但能在其基础上通过构建系统创建智能 Agent
- 为此,我们需要通过构建信息工程,让 AI 能够真正感知和改造世界,从而改变我们的生产进程
仅作展望。
引言
在开启正式讨论之前,我们希望从两个角度分别对 AI 进行讨论,从而夹逼出我们 从 AI 到 智能系统 的主题
- 形而上:我们尝试讨论 AI 智能的形态,进而发现 人类智能 的亮点
- 形而下:我们尝试给出 AI 使用的样例,进而发掘 人工智能 的痛点
结合二者,我们待解释一种通过人类智能引领人工智能跨越痛点的可能性
形而上者谓之道,形而下者谓之器;
化而裁之谓之变,推而行之谓之通,
举而措之天下之民,谓之事业。
以前只知前边两句,现在才知精髓全在后者
形而下者器:LLMs + DB 的使用样例
(为了不让话题一开场就显得那么无聊,我们先来谈点有意思的例子)
前些时日,简单尝试构建了一个原型应用,通过 LLM 的文本信息整合能力和推理能力,实现文本到情感表现的映射,并依此实现了游戏对话生成流水线中动作配置的自动生成。
该应用的工程步骤分为以下几步:
- 基于现有任务演出动作库和动作采用样例,构建一个使用情感表达向量化索引动作的数据库
- 向 LLMs 构建请求,通过向对话文本中添加情感动作标签丰富对话表现
- 召回填充完毕后的对话样本,正则化收集对话情感标签,并对数据库进行索引
- 召回数据库索引,逐句完成情感动作选择,并反解析至配档文件
这还是一个极简的工程原型,甚至 LLMs 在其中智能能力的发挥程度依旧存疑,但我主要还是希望其起到一个提醒作用:这彰显了所谓 “信息” 在实际开发、以及在后续将 AI 引入开发过程中的重要性。
我们要如何将原本储存于大脑的跨模态开发数据知识外化到一个可读的模态上并有效收集起来,同时要如何尽一切可能让 AI 能帮助我们挖掘数据中蕴含的价值,这是最核心的出发点。
而上面这一步,才是应对 LLM 的到来,在未来可期层面上最值得展开讨论的内容。
(后面会给出更多关联的讨论,这里就先不赘叙了)
形而上者道:对 LLM 既有智能能力及其局限性的讨论
这一节中,想讨论一下人工智能与人类智能的碰撞()
从 Plugins 到 AI 解决问题的能力
此相关的讨论是在 ChatGPT Plugins 出现后展开的:
ChatGPT Plugins 在两篇论文两个角度的基础上,对 LLMs 的能力的能力进行延拓
- ToolFormer:让 AI 具有使用工具的能力
- Decomp:让 AI 能逐层分解并完成任务
此相关的能力,其实在微软最新的一篇论文 TaskMatrix.AI 中被进一步阐述,其通过工程构建了一个 AI 能 自由取用 API 解决问题 的环境。
上述能力,在实质上进一步将 AI 解决问题的能力与人类进行了对齐:人们通过问题的拆解,将任务转化为自己能处理的多个步骤;并通过工具借自己所不能及之力,将问题最终解决。此二者无疑是人类解决问题最核心的步骤,即确定 “做什么” 和 “怎么做”
而这也基本奠定了后续面向 AI 的工作流,其基本展开形态:
- 为 AI 提供接口,为 AI 拓展能力
- 建模自身问题,促进有效生成
从人工智能到人类智能
在上面的论断中,我们看似已经能将绝大多数智能能力出让予 AI 了,但我还想从另一角度对 AI 与人类的能力进行展开讨论:
即讨论一下人工智能的模型基础与其历程
- 人工智能:AI 的元智能能力
- “人工” 智能:辅佐 AI 实现的智能
- 人类智能:于人类独一无二的东西
AI 智能的形态
大语言模型的原始目的是制造一个 “压缩器”,设计者们希望他能有效地学习世界上所有信息,并对其进行通用的压缩。
在压缩的过程中,我们希望 AI 丢掉信息表征,并掌握知识背后的智能能力与推理能力,从而使得该 “压缩器” 能在所有的域上通用。
该说法是略显抽象的,但我们可以给出一个简单的现实例子对其进行描摹:
“人总是要死的,苏格拉底也是人,所以苏格拉底是要死的”
这是一个经典苏格拉底式的三段论,其中蕴含着人类对于演绎推理能力的智慧。
假设上面的样本是 LLM 既有学习的,而这时来了一个新的样本:
“人不吃饭会被饿死,我是人,所以我也是要恰饭的嘛”
那么对于一个理想的智能压缩器而言,其可能发现新句与旧句之间的关联,并有效学习到了句子的表征形式及其背后的逻辑
而随后,压缩器会倾向于储存三段式推理这一智能结构,并在一定程度上丢弃后来的(人,我,恰饭)这一实体关系组,仅简单建模其间联系,并在生成时按需调整预测权重。
换言之,对 LLMs 而言,其对 “智能” 的敏感性要远高于 “信息”
而这也带来了大语言模型训练的一些要点,通常对 LLM 而言,越是底层的训练越容易混入并给予 LLM “信息表征”,而越是高层的训练,越倾向于让 LLM 掌握新的 “智能模式”
基于这一点,我们能对 LLM 的智能能力出发点进行简要推断:
LLM 的实质上还是通过 “语言结构” 对 “外显人类智能” 进行掌握,也正是相应的,引入了一系列问题
- AI 偏好学习智能,却不能很好的学习 “信息型知识”
- AI 只能掌握基于语言模态等可外显表征模态下的智能
进一步的,受限于自回归解码器结构的限制,AI 只能线性地回归文本序列,而无法构建自反馈。
而也正是这些固有缺陷,为人类的自我定位和进一步利用 AI 找到了立足点。
赋能 AI 实现智能
作为上面一点的衍生,我们可以从大体两个角度去辅助 AI 智能的实现:
补全 AI 的智能能力
通过 Prompt Engineering 激发 AI 既有的能力
通过启发方法构建 AI 的智能链条
- 内隐启发:通过复杂 Prompt 指导 AI 理解并完成任务 ICL / COT Prompt
- 外显启发:通过程序规范化 LLMs 完成任务所需流程 ChatGPT Plugins / LangChain
- 结构启发:通过构建工程结构支持 AI 自迭代分解并解决问题 Decomp / TaskMatrix.AI/ Hugging GPT
附加 AI 的信息能力
- 通过知识工程和迭代调用等方法,为 AI 构造 “记忆宫殿”
反思人类智能
作为人类而言,我们所拥有的智能能力显然也不是能被 AI 所覆盖的
首先,我们是 “能动” 与 “体验” 功能都脱离于我们狭义的智能而存在,而正是这些要素赋予了我们 “主体性”
其次,也正是这些成分脱离于语言和表达而存在,使他们成为无法被显式学习的要素
- AI 不具备深层动机,它有的只是被语言所描述的目标
- AI 不具备体验能力,因此它的创作是无反馈无迭代的
但是,相应的,不涉及上述内容的工作流程,在可预见的将来,会由 AI 全面参与。
而我们为了不被时代淘汰,要更加积极主动地将 AI 引进来。
化而裁之,推而行之:回到我们的主题
回顾一下上文,我们从应用和概念两个角度简要讨论了 AI 当前的使用情况,以及这些应用依托于什么
应用
- 通过 AI 实现了高度智能化的工作
- 通过整理开发信息使得链路通顺
概念
- 我们能通过外力引导赋予 AI 更强的解决问题的能力
- AI 的核心能力是通用智能能力,对工作情境已高度可用
- 人类能力的核心是能动和体验,而非浅显的智能
展望
- 如何更好的赋能 AI
- 如何更好的驾驭 AI
在唠嗑了这么多之后,我们终于能引入今天的主题了。
简而言之,我希望能追随着 AI 的发展,讨论是否能构建这样一个通用的 AI 框架,并将其引入工作生产的方方面面。希望能讨论及如何对生产信息进行有效的管理,也包括如何让我们更好调用 AI,如何让 AI 满足我们的生产需要。
LLMs:生成原理及能力考察
相信无论是否专业,各位对 LLMs 的生成原理都有着一定的认知
简单来说,这就是一个单字接龙游戏,通过自回归地预测 “下一个字”。在这个过程的训练中,LLMs 学习到了知识结构,乃至一系列更复杂的底层关联,成为了一种人类无法理解的智能体。
In-Context Learning / Chain of Thought
经过人们对模型背后能力的不懈考察,发现了一系列亮点,其中最瞩目的还是两点:
ICL(In-Context Learning,上下文学习)和 COT(Chain of Thought,思维链)
可以说,绝大部分对于使用 LLMs 的启发,都源自这两个特性,简单说明此二者的表现
- ICL:上下文学习使得模型能从上下文中提供的样例 / 信息中学习,有效影响输出
- COT:当模型在输出过程中写出思维过程时,能大幅提升输出效果
虽然学界对此没有太大的共识,但其原理无非在于给予 LLMs 更翔实的上下文,让输出与输入有着更紧密的关联与惯性。(从某种意义上来说,也可以将其认为是一种图灵机式的编程)
ICL:
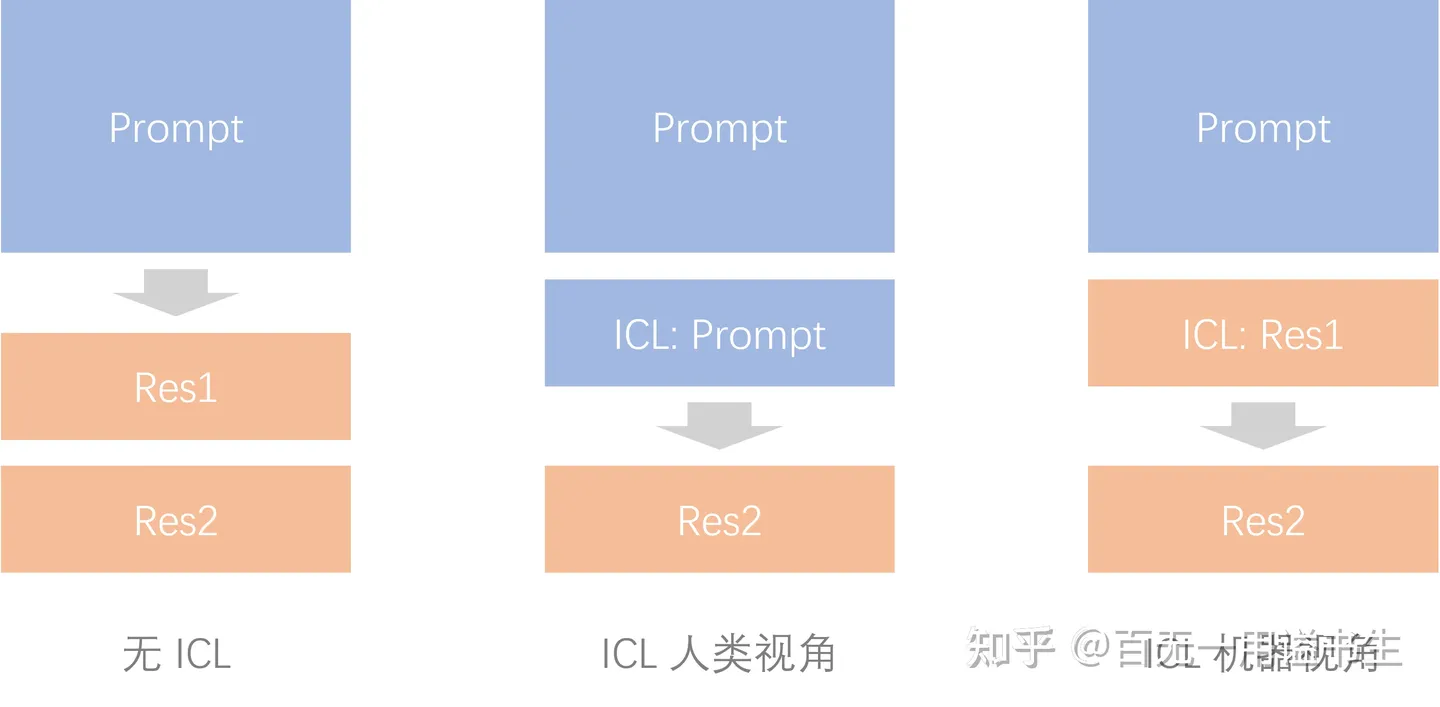
ICL 为输出增加惯性
可以简单认为,通过 ICL Prompt,能强化人类输入到机器输出的连贯性,借以提升输出的确定性。
在经过 “回答” 的 finetune 之前,大模型的原始能力就是基于给定文本进行接龙,而 ICL 的引入则在 “回答” 这一前提条件下,降低了机器开始接龙这一步骤中的语义跨度,从而使得输出更加可控。
COT: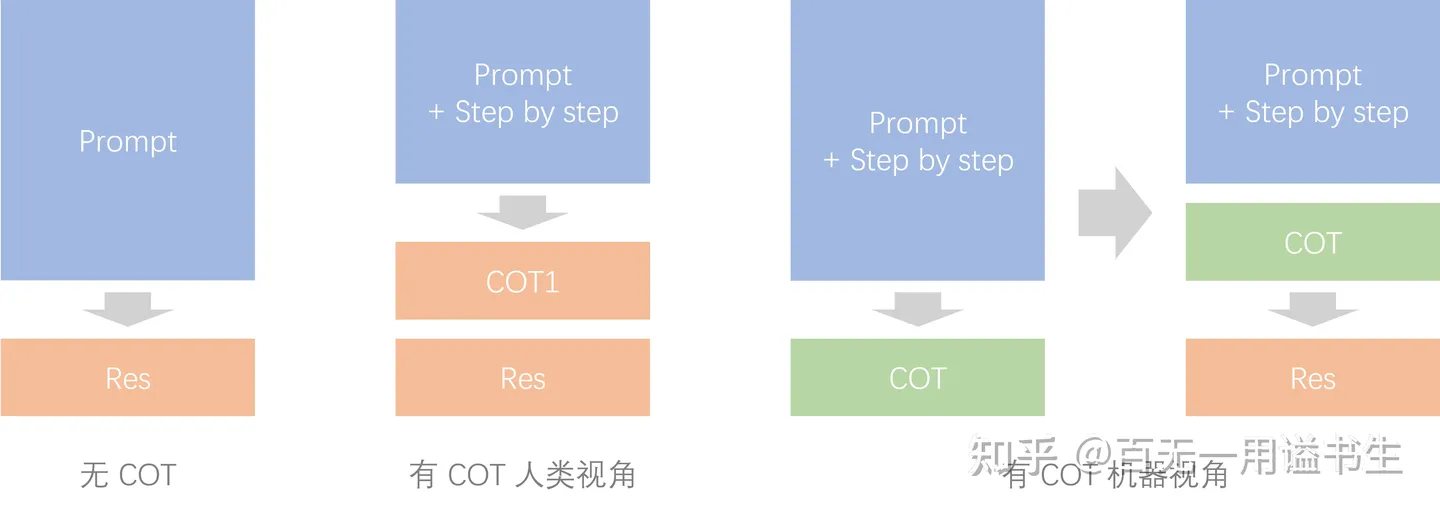
COT 为输出增加关联
同样可以简单认为,在引入 COT 后,AI 能将一次完整的输出看作两次分离的输出。
对这两次输出而言,输入输出之间均有更高的关联度,避免了长程的抽象推理。对应短程推理的误差相对较小,最终使得积累误差也要更小。
进一步的,ICL 的发现,让 LLMs 能避免过多的传统 Finetune,轻易将能力运用在当前的情景中;COT 的发现,使得通过 LLMs 解决复杂问题成为可能。此二者的组合,为 LLMs 的通用能力打下了基础。
TaskMatrix.AI
微软对 TaskMatrix.AI 这一项目的研究,很大程度上展示了 LLMs 基于 ICL 和 COT 所能展现的能力
(需要注意的是,TaskMatrix.AI 更大程度上是一个愿景向的调研案例,尚未正式落地生态)
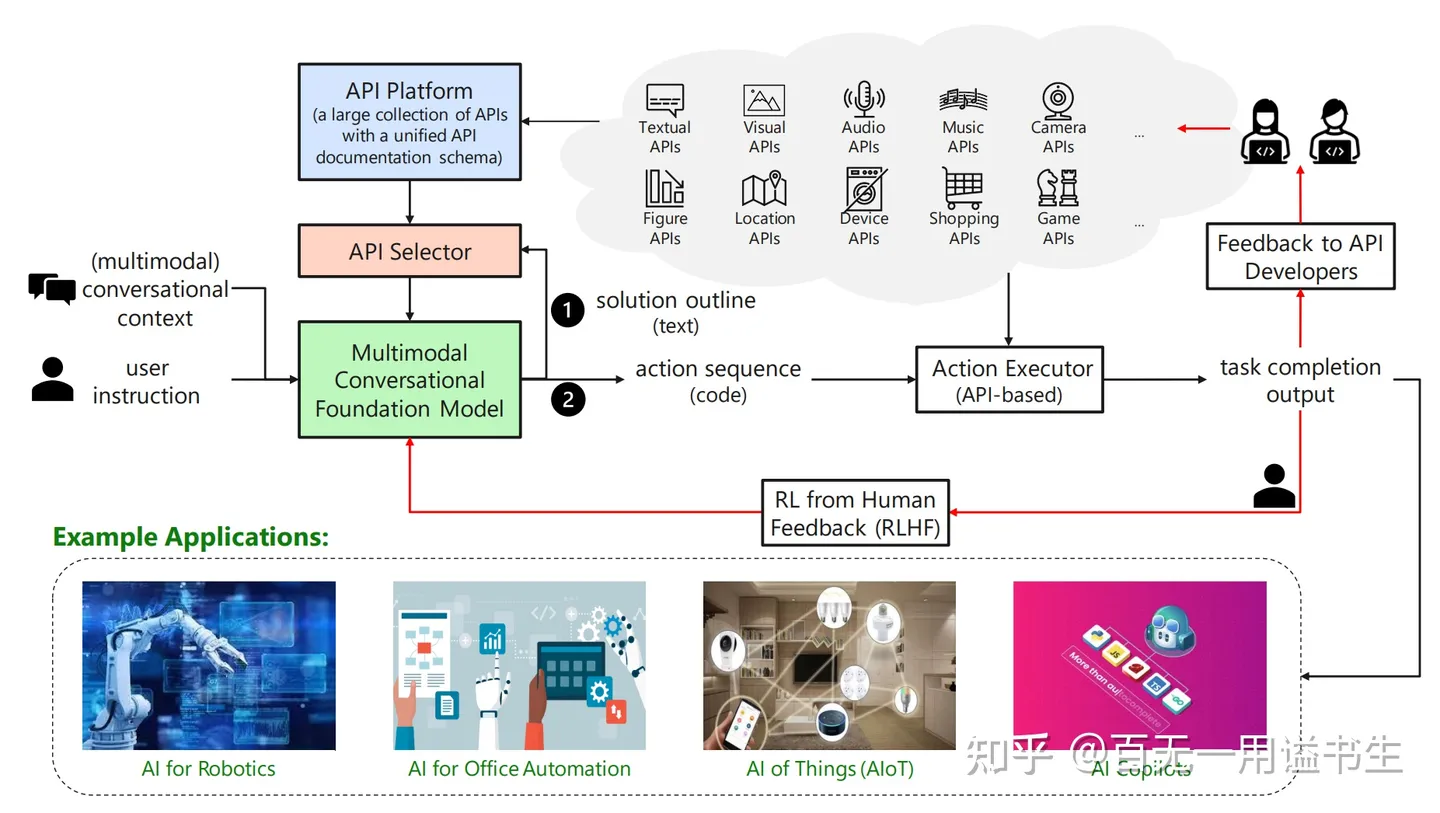
TaskMatrix 的生态愿景
该文展现了一个生态愿景,即将 LLMs 作为终端,整合诸多 API 的能力,让 AI 运用在生活中的方方面面。
简单介绍的话,该框架主要分为四个模块
- Multimodal Conversational Foundation Model:通过与用户对话了解问题情景,并按需组装 API 实现操作,帮助用户解决问题
- API Platform:构建统一的 API 制式,储存和管理平台内上所有 API 及其关联文档
- API Selector:根据 MCFM 对用户问题的理解,向 MCFM 选择并推荐可用 API
- API Executor:代替 MCFM 执行 API 脚本,并返回执行结果或中间信息
基于这一框架,微软于论文中实现了诸如图像编辑(基于我们摸不到的 GPT4)、论文写作、PPT 制作等工作。不难想象,微软即将推出的 Office 365 Copilot 也是基于相关技术及更深层的 API 定制实现的。
而与此相关的工作还可以关注 HuggingGPT,也是微软同期发布的论文,让 AI 能自主调用 Hugging Face 上的通用模型接口解决 AI 问题,从而实现一种 “AGI” 性能。
毫无疑问,我们通常会认为这种通过构造框架来大幅增强 LLMs 能力的可能性,是构建在既有 ICL 和 COT 的能力之上的,而我会围绕此二者重新进行简单展开
(当然,硬要说的话,对 ICL 和 COT 两种能力都有一个狭义与广义之争,但这不重要,因为我喜欢广义)
ICL for TaskMatrix
狭义的 ICL:从输入的既有样例中学习分布和规范
广义的 ICL:有效的将输入内容有效运用到输出中
以 TaskMatrix 为例,在 API 组装阶段,其为 MCFM 提供的 ICL 内容即为 API 的文档
以论文为例,其提供的每个 API 文档分为如下部分
- API Name:用于描述该 API 名,亦即函数的调用名
- Parameter List:用于描述 API 中的参数列表,介绍每个参数的特性及输入输出内容
- API Description:API 描述,用于描述 API 功能,查找 API 时的核心依据
- Usage Example:API 的调用方法样例
- Composition Instruction:API 的使用贴士,如应该与其它什么 API 组合使用,是否需要手动释放等
样例:打开文件 API

基于此类文档内容和 ICL 的能力,LLMs 能从输入中习得调用 API 的方法,依此快速拓展了其横向能力
COT for TaskMatrix
狭义的 COT:通过 Lets Think Step by Step 诱导 LLMs 生成有效的解答中间步骤,辅助输出
广义的 COT:通过 LLMs 的固有能力对问题进行拆解,构建解决问题的链条
通过此种模式,能极好的将问题分解至可被执行的原子形态
在 TaskMatirx 中,通过该模式,让 MCFM 将任务转化为待办大纲,并最终围绕大纲检索并组合 API,完成整体工作
样例:写论文
构建完成工作大纲

TaskMatrix 自动围绕目标拆解任务
自动调用插件和组件

TaskMatrix 自动为任务创建 API 调用链
初步考察
基于上述的简单介绍,我们已经初步认识了 AI 在实际情景中的高度可用性
而接下来,我们继续从工程的角度揭示这种可用性的根源 —— 其源自一项通用的 Prompt 技术
Prompt Decomposition:方法论
我们可以认为,TaskMatirx 的能力极大程度上依托于 Prompt Decomposition 的方法
而这实质上也是串联 LLM 能力与实际工程需求的必经之路
[2210.02406] Decomposed Prompting: A Modular Approach for Solving Complex Tasks (arxiv.org)
原始 Decomp
Decomp 的核心思想为将复杂问题通过 Prompt 技巧,将一个复杂的问题由 LLMs 自主划分为多个子任务。随后,我们通过 LLMs 完成多个任务,并将过程信息最终组合并输出理想的效果

几种 Prompt 方法图示
参考原始论文中阐述的方案,Decomp 方法区别于传统 Prompt 方法就在于,Decomp 会根据实际问题的需要,将原始问题拆解为不同形式的 Sub-Task,并在 Sub-Task 中组合使用多种符合情景的 Prompt 方法。
而对于 Decomp 过程,则又是由一个原始的 Decomp Prompt 驱动

Decomp 方法执行样例
在实际运行中,Decomp 过程由一个任务分解器,和一组程序解析器组成
其中分解器作为语言中枢,需要被授予如何分解复杂任务 —— 其将根据一个问题 Q 构建一个完整的提示程序 P,这个程序包含一系列简单的子问题 Q_i,以及用于处理该子问题的专用函数 f_i(可以通过特定小型 LLM 或专用程序,也可以以更小的提示程序 P_i 形式呈现)。
模型将通过递归运行完整的提示程序,来获得理想的答案。
在构建 Decomp 流程的初期,其主要是为了解决 LLMs 无法直接解决的具有严密逻辑的工作(比方说基于文本位置的文字游戏,比方说检索一首藏头诗的头是啥(当然这个太简单了),大模型的位置编码系统和概率系统让其很难长程处理相关工作),我们希望通过 Decomp 方法,将复杂问题逐步归约回 LLMs 能处理的范畴。
我们也可以认为,在每个子任务中,我们通过 Prompt 将 LLMs 的能力进行了劣化,从而让其成为一个专职的功能零件。而这种对单个 LLMs 能力迷信的削减,正延伸出了后续的发展趋势。
Decomp 衍生
Decomp 的原始功能实际上并不值得太过关注,但我们急需考虑,该方法还能用于处理些什么问题。
递归调用
我们可以构建规则,让 Decomp 方法中的分解器递归调用自身,从而使得一个可能困难的问题无限细分,并最终得以解决
外部调用
通过问题的分解和通过 “专用函数” 的执行,我们可以轻易让 LLMs 实现自身无法做到的调用 API 工作,例如主动从外部检索获取回答问题所需要的知识。

Decomp 方法调用外部接口样例
如上图为 LLMs 利用 ElasticSearch 在回答问题过程中进行检索
基于此,我们还希望进一步研究基于这些机制能整出什么花活儿,并能讨论如何进一步利用 LLMs 的能力
回顾:HuggingGPT 对 Decomp 方法的使用
HuggingGPT 一文也许并未直接参考 Decomp 方法,而是用一些更规范的手法完成该任务,但其充分流水线化的 Prompt 工程无疑是 Decomp 方法在落地实践上的最佳注脚

HuggingGPT
如图所示,在实际工程中,对于这个调用 HuggingFace API 的 “通用人工智能” 而言,其所需的任务并不复杂,仅仅分为三步(获取并运行缝在一起了)
- 理解并规划解决问题所需步骤
- 选择并运行解决问题所需模型
- 基于子问题输出结果总结反馈
同样的,TaskMatrix.AI 也使用了相似的方法和步骤来完成任务,最新的进展高度明晰了该框架的可用性,并为我们如何有效使用 AI 来完成专用任务提供了有效的指导。
接下来,我们会讨论一个很新的,在为 Agent 模拟任务构建框架上,把 Decomp 和 Prompting 技术用到登峰造极的样例。
Generative Agents:社群模拟实验
[2304.03442] Generative Agents: Interactive Simulacra of Human Behavior (arxiv.org)
Generative Agents 一文通过的自然语言框架 AI 构建出了一个模拟社群,一方面我们震撼于以 AI 为基础的社群复杂系统也能涌现出如此真实可信的表现,另一方面则需要关注他们通过 Prompt 技巧和工程设计,为 AI 构建的 感知、记忆、交互 大框架。
其在极大程度上能为我们想建立的其它基于 AI 的工程提供参考。
因为,其本质是一个信息管理框架的实验。
简要介绍
简单介绍该项目构建的框架:
我们可以认为该工程由三个核心部分构成
- 世界信息管理
- 角色信息管理
- 时间驱动机制
我们可以从宏观到微观渐进讨论该课题:
Generative Agents 构建了一套框架,让 NPC 可以感知被模块化的世界信息。同时,对于全游戏的每个时间步,该框架驱动 NPC 自主感知世界环境的信息与自身信息,并依此决策自己想要执行的行为。
根据 NPC 的决策,NPC 能反向更新自身所使用的记忆数据库,并提炼总结出高层记忆供后续使用。
世界沙盒的构建
相比角色信息的构建是重头戏,世界沙盒的构建使用的方法要相对朴素一些
世界沙盒的核心是一个树状 Json 数据,其依据层次储存游戏场景中所有的信息:
- 一方面,其包含场景中既有对象,包括建筑和摆件等的基础层级信息
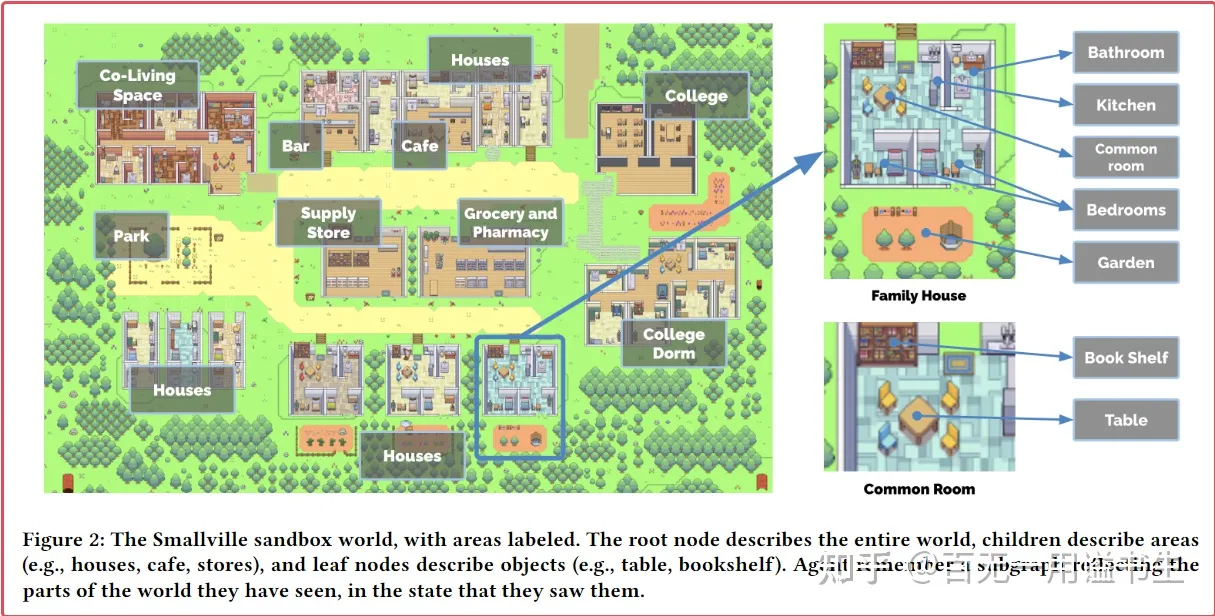
Generative Agents 的场景信息管理
- 另一方面,其储存了沙盒世界中每个代理的信息,包括其位置、当前动作描述、以及他们正在交互的沙盒对象
对于每个时间步,服务器将解析场景的状态,例如对于 Agent 使用咖啡机的情景,会自动将咖啡机转换为正在使用中的状态。
而相对更有趣的设计是,场景中的所有信息会依靠认知过滤(即 NPC 是否能感知其感知范围外的环境变化)进行筛选,并最终呈现成 NPC 可感知 / 有印象的子集。
同时,空间信息会被自动组成自然语言 Prompt,用于帮助 Agent 更好地理解外部信息。甚至当 Agent 希望获取空间信息时,其能主动递归调用世界信息,从而让 NPC 能准确找到其希望抵达的叶子节点。
Agent 构建
模型中的 Agent 由 数据库 + LLMs 构建
对于一个初始化的 Agent,会将角色的初始设定和角色关联设定作为高优先级的 “种子” 储存在 “记忆” 中,在记忆种子的基础上,得以构建角色的基本特征和社交关系,用于展开后续关联
一个 Agent 核心的能力是 —— 将当前环境和过去经验作为输入,并将生成行为作为输出
对于当前环境,在构建世界沙盒模块对方法论进行了简要的介绍。
而对于过去经验的输入,则是文章的一大亮点
记忆模式
对于 Agent 的记忆,依托于一个储存信息流的数据库
数据库中核心储存三类关键记忆信息 memory, planning and reflection
Memory
对于 Agent 每个时间步观测到的事件,会被顺序标记时间戳储存进记忆数据库中
而对于储存进数据库的信息,记忆管理器通过三个标准对其进行评估和管理
- Recency:时效性,记忆在数据库中会随着时间推移降低时效性,数据库储存记忆的最后访问时间,并由此与当前时间对比,计算时效性评分
- Importance:重要性,当记忆储存时,会使用特定 Prompt 让 Agent 自主评估当前记忆的重要性,并依据该评分调整该记忆的权重(例如扫地和做咖啡可能就是无关紧要的记忆)
- Relevance:关联性,该指标被隐式地储存,表现为一个嵌入索引,当调取记忆时,会将调取记忆的关键词嵌入与索引相匹配,以取得关联性的评分
对于对记忆数据库进行索引的情况,会实时评估上述三个指标,并组合权重,返回对记忆索引内容的排序
Reflection
反思机制用于定期整理当前的 memory 数据库,让 npc 构建对世界和自身的高层认知
反思机制依靠一个自动的过程,反思 - 提问 - 解答
在这个过程中,Agent 需要复盘自身所接受的记忆,并基于记忆对自己进行追问:
“根据上述信息,我们能问出哪些最高优先级(有趣)的问题”
依据由 Agent 的好奇自主产生的问题,我们重新索引数据库,并围绕相关的记忆产生更高层的洞察
What 5 high-level insights can you infer from the above statements?
(example format: insight (because of 1, 5, 3))
进一步的,我们将这些洞察以相同的形式重新储存至记忆库中,由此模拟人类的记忆认知过程
Planning
Planning 的核心在于鼓励 Agent 为未来做出一定的规划,使得后续行动变得可信
计划由 Agent 自行生成,并存入记忆流中,用于在一定程度上影响 Agent 的当前行为
对于每天 Agent 都会构建粗略的计划,并在实际执行中完善细节
在此基础上,Agent 也需要对环境做出反应而调整自己的计划表(例如自身判断外界交互的优先级比当前计划更高。
交互构建
基于上述记忆框架,进一步实时让 Agent 自行感知并选择与其它 Agent 构建交互
并最终使得复杂的社群在交互中涌现
启发
Generative Agent 框架主要带来了一些启发,不止于 AI-NPC 的构建,其操作的诸多细节都是能进一步为我们在实际的工程中所延拓的。
例如:
感知,围绕目标递归对地图搜索,带来了递归检索数据库的可能性,以及要如何有效构建数据库之间的关联(不止于树
记忆,将 AI 的 Reflection 等表现储存进数据库中,用于实现高层观点的构建,比方说自动构建对复杂对象,如代码库的高层理解
交互,通过地图要素的拆分和可读化构建的交互框架,如何基于该思路构建大世界地图关卡数据的数据库,如何把它拓展到更复杂的游戏中
我们可以认为,Generative Agents 一文的核心亮点在于,其构建了一套充分有效的信息管理机制以支撑世界运行的需要,并未我们提供了一系列启发性的数据管理观点
- 层次管理数据:通过对数据进行分层的管理和访问,降低运算开销,并通过系统级递归实现访问
- 层次管理信息:通过语言模型的能力为信息构建高层的 Insight,对碎片信息的信息量进行聚合
- 数据价值评估:通过实际需求对信息进行评估,构建多样化的信息评估指标,实现信息的有效获取
- AI x 信息自动化系统的构建:基于 AI + 软件系统而非基于人工对数据进行收集和管理
- etc...
AutoGPT:自动化的智能软件系统
Torantulino/Auto-GPT: An experimental open-source attempt to make GPT-4 fully autonomous. (github.com)github.com/Torantulino/Auto-GPT
同为近期,一个名为 AutoGPT 的软件系统在 Github 上被开源,其通过构建软件系统支持,让 AI 能围绕预设定的目标反复迭代,并自主获取外界的反馈,从而形成一个能自动化满足需求的自动机。
特别的,其可以被视为前文中 Generative Agent 中由系统自驱动单个 Agent 的拓展,通过构建内置和外置的不同目标驱动 GPT 作为 Agent 持续运行
AutoGPT 主要特性如下:
- 使用 GPT-4 实例进行文本生成
- ️ 使用 GPT-3.5 进行文件存储和摘要
- 接入互联网获取信息
- 长期和短期内存管理
考虑到工程细节,该项目实际上没有特别大的落地案例,但毫无疑问这是面向未来的 GPT 使用方式
其核心机制在于,通过 LLMs 和 记忆 / 目标管理模块 的符合,构建出了一个复杂的 Agent 系统
我们通常不再将该系统认为是一个完整的 GPT 线程:
这是一个通过工程、通过系统化、通过反馈构建的自动机,就像人一样。
(我们需要放下通过 LLMs 来模拟智能体的执念,我们作为智能体的实质是一个输入输出的系统,而我们所自认为的自由意志也只是大脑的一个解释模块而已,也许与智能系统中调用的单个 LLMs 线程异曲同工)
当前,AutoGPT 的能力主要反应在主动通过 Google API 联网,寻找并记忆自己需要使用到的知识,包括某些软件的接口和其它 API,也包括自己完成某些分析所需要的知识。
(已经有人尝试通过其快速构建软件工程,或者完成其它某些自动化操作。)
(虽然感觉依旧不甚理想)
(如下是 AutoGPT 的基础 Prompt)
[
{
'content': 'You are Eliza, an AI designed to write code according to my requirements.\n'
'Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.\n\n'
'GOALS:\n\n'
'1. \n\n\n'
'Constraints:\n'
'1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.\n'
'2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.\n'
'3. No user assistance\n'
'4. Exclusively use the commands listed in double quotes e.g. "command name"\n\n'
'Commands:\n'
'1. Google Search: "google", args: "input": "<search>"\n'
'2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"\n'
'3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"\n'
'4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"\n'
'5. List GPT Agents: "list_agents", args: \n'
'6. Delete GPT Agent: "delete_agent", args: "key": "<key>"\n'
'7. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"\n'
'8. Read file: "read_file", args: "file": "<file>"\n'
'9. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"\n'
'10. Delete file: "delete_file", args: "file": "<file>"\n'
'11. Search Files: "search_files", args: "directory": "<directory>"\n'
'12. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"\n'
'13. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"\n'
'14. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"\n'
'15. Execute Python File: "execute_python_file", args: "file": "<file>"\n'
'16. Execute Shell Command, non-interactive commands only: "execute_shell", args: "command_line": "<command_line>"\n'
'17. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"\n'
'18. Generate Image: "generate_image", args: "prompt": "<prompt>"\n'
'19. Do Nothing: "do_nothing", args: \n\n'
'Resources:\n'
'1. Internet access for searches and information gathering.\n'
'2. Long Term memory management.\n'
'3. GPT-3.5 powered Agents for delegation of simple tasks.\n'
'4. File output.\n\n'
'Performance Evaluation:\n'
'1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n'
'2. Constructively self-criticize your big-picture behavior constantly.\n'
'3. Reflect on past decisions and strategies to refine your approach.\n'
'4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.\n\n'
'You should only respond in JSON format as described below \n'
'Response Format: \n'
'{\n'
' "thoughts": {\n'
' "text": "thought",\n'
' "reasoning": "reasoning",\n'
' "plan": "- short bulleted\\n- list that conveys\\n- long-term plan",\n'
' "criticism": "constructive self-criticism",\n'
' "speak": "thoughts summary to say to user"\n'
' },\n'
' "command": {\n'
' "name": "command name",\n'
' "args": {\n'
' "arg name": "value"\n'
' }\n'
' }\n'
'} \n'
'Ensure the response can be parsed by Python json.loads',
'role': 'system'
},
{
'content': 'The current time and date is Fri Apr 14 18:47:50 2023',
'role': 'system'
},
{
'content': 'This reminds you of these events from your past:\n\n\n',
'role': 'system'
},
{
'content': 'Determine which next command to use, and respond using the format specified above:',
'role': 'user'
}
]回归正题:AI 作为智能系统
作为正题的回归,我们需要重新考虑什么是一个 AI,一个能帮助我们的 AI 应当处于什么样的现实形态?
我们需要的 AI 仅仅是大语言模型吗?如果是,它能帮我们做什么呢?如果不是,那 AI 的实质是什么呢?
我首先武断地认为,我们需要的 AI,并不是一个语言模型实体,而是一个复杂智能系统
而上述围绕 GPT 展开的实验,实质都是上述观点的佐证。
接下来,我们会围绕此进行展开
意识理论之于 AI:全局工作空间理论
全局工作空间理论(英语:Global workspace theory,GWT)是美国心理学家伯纳德・巴尔斯提出的意识模型。该理论假设意识与一个全局的 “广播系统” 相关联,这个系统会在整个大脑中广播资讯。大脑中专属的智能处理器会按照惯常的方式自动处理资讯,这个时候不会形成意识。当人面对新的或者是与习惯性刺激不同的事物时,各种专属智能处理器会透过合作或竞争的方式,在全局工作空间中对新事物进行分析以获得最佳结果,而意识正是在这个过程中得以产生。
这通常被认为是 神经科学家接受度最高的哲学理论
从某种意义上来说,该理论将 “系统” 摆在了主体的位置,而把纯粹的语言或 “意识” 转变成了系统运动的现象,表现为系统特殊运作情况的外显形式。
其提醒我们,就连我们的意识主体性,也只是陈述自我的一个表述器而已。我们是否应当反思对语言能力的过度迷信,从而相信我们能通过训练模型构建 All in One 的智能实体?
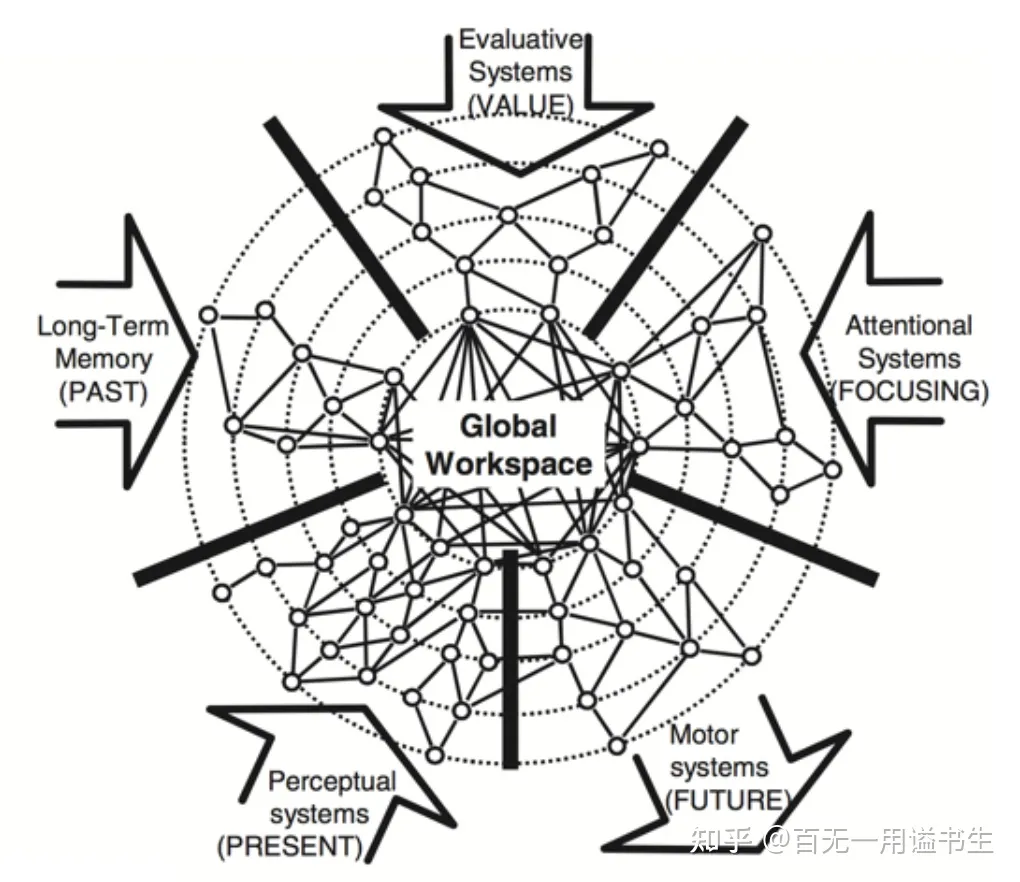
全局工作空间理论
如图所示,在全局工作空间理论的建模中,全局工作空间作为系统,有五个主要的模块负责输入和输出
其分别是:
- 长时记忆(过去)
- 评估系统(价值)
- 注意系统(关注)
- 知觉系统(现在)
- 运动系统(未来)
例子:意识系统 For Generative Agent
单独解释的话,或许会比较麻烦,毕竟我对认知科学并不专业
我们可以简单对比 Generative Agents 其框架,结合意识模型讨论 Agent 是如何被有效构建的
回顾前文,我们核心对照 Agent 的记忆模块构建:
(不想手写,让 GPT4 来进行代笔)
从全局工作空间理论(GWT)的角度来看,Generative Agent 的设计确实与之有相似之处。GWT 提出了一个全局工作空间,负责整合来自不同认知子系统的信息。在 Generative Agent 的框架中,这些认知子系统可以看作是上述提到的几个模块。
- 首先,我们可以将长时记忆(过去)与 Generative Agent 的 memory 模块进行类比。memory 模块中存储了 Agent 在过去时间步观察到的事件,这与长时记忆中存储的过去信息相对应。
- 其次,评估系统(价值)可以与 Generative Agent 的 Importance 和 Relevance 进行对应。Importance 可以理解为对记忆的重要性评估,而 Relevance 则评估了记忆与当前情境的关联性。这两者与全局工作空间理论中对不同认知子系统信息的竞争和广播过程相呼应。
- 注意系统(关注)可以与 Generative Agent 的 Recency 相关联。Recency 衡量了记忆的时效性,这类似于在全局工作空间中,我们需要关注当前环境中的新信息,以便及时做出反应。
- 知觉系统(现在)在 Generative Agent 中可以对应于当前环境的输入,这与全局工作空间理论中的感知子系统相一致。
- 运动系统(未来)可以与 Generative Agent 的 planning 和 reflection 模块相关联。planning 模块让 Agent 为未来做出规划,而 reflection 模块则允许 Agent 对过去的记忆进行整理,构建高层认知,进而影响未来的行为。这两个模块与全局工作空间理论中的行动子系统相呼应。
综上所述,Generative Agent 的设计确实与全局工作空间理论有相似之处,通过将这些模块整合到一个统一的框架中,Agent 能够模拟人类在虚拟世界中扮演角色进行交互。这种整合有助于理解大脑如何处理和整合来自不同认知来源的信息,从而实现更接近人类的智能行为。
当然,我个人对该问题的认知与 GPT4 并非完全相同,包括注意系统与运动系统的部分。但其实我并不一定需要将所有东西全都呈现出来,因为在框架上它已然如此。
记忆、评估、反思这几块的设计通过 Prompt 把 LLMs 劣化成专用的智能处理器单元,并系统性实现信息的整合与输出。从整体的观点上来看,Generative Agents 中的 Agent,其主体性并不在于 LLM,而是在于这个完整的系统。(相应的,LLMs 只是这个系统的运算工具和陈述工具)
例子:AutoGPT 的考察
我们再从相同的角度考察 AutoGPT 这一项目:
- 内存管理:全局工作空间理论强调了长时记忆、短时记忆和注意力机制之间的互动。AutoGPT 中的长期和短期内存管理与此类似,需要智能体在执行任务时权衡信息的重要性、时效性和关联性,以便有效地组织和存储信息。
- 信息获取:全局工作空间理论的知觉系统负责处理来自外部的信息。AutoGPT 通过搜索和浏览网站等功能,获取外部信息,这与知觉系统的作用相符。
- 生成与执行:全局工作空间理论中的运动系统负责生成和执行行为。AutoGPT 通过多种命令实现了文本生成、代码执行等功能,体现了运动系统的特点。
同时,其也具有对应的缺陷:
- AutoGPT 的长期记忆存在较大漏洞,并没有较强的注意力能力
- AutoGPT 不能围绕记忆擢升更高层的认知,从而进一步指导未来的行为
- AutoGPT 的运动系统,即执行能力受限于 Prompt 提供的接口,无法自适应完成更多任务
- AutoGPT 对自身既往行为认知较差,短期记忆依赖于 4000 字 Context 窗口,并被系统输入占据大半
这也对应 AutoGPT 虽然看似有着极强的能力,但实际智能效果又不足为外人道也
构建一个什么样的智能系统
再次回归正题,Generative Agents 和 AutoGPT 这两个知名项目共同将 AI 研究从大模型能力研究导向了智能系统能力研究。而我们也不能驻足不前,我们应当更积极地考虑我们对于一个 AI 智能体有着什么样的需求,也对应我们需要构建、要怎么构建一个基于 LLMs 语言能力的可信可用的智能系统。
我们需要从两个角度展开考虑,从我们需要什么展开,并围绕框架进行延拓
当前,ChatGPT 虽然成了炙手可热的明珠,但却依然存在一些微妙的问题
来自 即刻网友 马丁的面包屑
观察到一些现象:
1. 除了最早期,最成熟的 Jasper 这样围绕短文本生成领域的应用,还没有看到太颠覆性的大模型应用
2. 从 GPT-4 发布后的狂欢,其实是应用上的狂欢,无论 HuggingGPT、AutoGPT、Generative Agent 本质上是一种 “玩法” 的挖掘。
3. 这种 Demo 级的产品展现了创意,但是我们知道 Demo 离最终落地还有非常多要解决的问题,这些问题哪些是可控的只需要堆时间,哪些是不可控的需要基座模型升级目前还看不清楚。
4. 另外我在尝试将他融入我的工作流,帮助有限。我让一些程序员朋友测试 Github Copilot,评价上也比较有限
该讨论中所展现的问题,其核心在于,如何真正将 GPT 沉入 “场景” 中去。
而这才是真正一直悬而未决的 —— 作为一个打工人,你真正需要帮助的那些场景,GPT 都是缺席的。
同时,这样的场景,他是一个活场景抑或死场景?在这样的场景上,我们是否需要一个全知的神为我们提供信息?还是说,我们想要的是一个能像我们一样在场景中获取信息,并辅助我们决策 / 工作的个体?
这些问题都在指导、质问我们究竟需要一个怎样的智能系统。
予智能以信息:难题与展望
回到最开始的话题,我们构建一个可用智能系统的基底,依旧是信息系统
我们大胆假设,如果我们希望构建一个足以帮助我们的智能系统,其需要拥有以下几个如 全局工作空间理论 1 所述的基本模块
知觉系统(现在)
工作记忆(中继)
- 长时记忆(过去)
- 评估系统(价值)
- 注意系统(关注)
运动系统(未来)
而接下来,我们希望对其进行逐一评估,讨论他们各自将作用的形式,讨论他们需要做到哪一步,又能做到哪一步。
知觉系统:构建 AI 可读的结构化环境
知觉系统负责让智能体实现信息的感知,其中也包括对复杂输入信息的解析
举两个简单的例子,并由此引出该课题中存在的难题
AutoGPT 的知觉设计:结构性难题
AutoGPT 所使用的 Commands 接口中,就有很大一部分接口用于实现知觉
典型的包含 Google Search & Browse Website & Read file
Google Search: "google",
- args: "input":
"<search>" - 返回网页关键信息与网址的匹配列表
- args: "input":
Browse Website: "browse_website",
args:
- "url":
"<url>", - "question":
"<what_you_want_to_find_on_website>"
- "url":
返回网址中与 question 相关的匹配文段(通过 embedding 搜索)
Read file: "read_file",
- args: "file":
"<file>" - 读取文件并解析文本数据
- args: "file":
这些访问接口由程序集暴露给 GPT,将知觉系统中实际使用的微观处理器隐藏在了系统框架之下
AutoGPT 所实际感知的信息为纯文本的格式,得益于以开放性 Web 为基础的网络世界环境,AutoGPT 能较方便地通过搜索(依赖于搜索引擎 API)和解析 html 文件(依赖于软件辅助,GPT 难以自行裁剪 html 中过于冗杂的格式信息),从而有效阅读绝大多数互联网信息。
但显然的,Read file 接口能真正有效读取的就只有纯文本文件此类了。
由此,这带来了知觉系统设计的第一个难题:我们要如何面对生产环境中的一系列非结构化信息?如何对其进行规范和整理?如何设计 “处理器” 使得 GPT 能有效对其进行读取?
围绕这一难题,我们简单例举几个例子来进行讨论,用作抛砖引玉:
- 我们以 Excel 或 Word 等格式编写排版的策划文档,要如何让 GPT 读取和索引?
- 如果我们希望让 GPT 掌握游戏中的关卡信息,其要如何对关卡编辑器进行理解?
- 如果我们有一个数千行的代码文件,如何让 GPT 能掌握其结构信息,充分理解模功能,而非因为草率输入爆掉上下文限制?
- 如果我们希望让 GPT 帮助我们通过点击 UI 要素自动测试游戏,我们要如何向其传达当前界面 UI 结构?如何向其展示测试进程和玩家状态?
- etc...
综上所述,第一个难题就是,我们要如何为所有期待由 AI 帮忙解决的问题,构造 AI 能理解的语境,如何把所有抽象信息规范化、结构化地储存(不止步于文本,而是把更多东西文本化(顺便这里的文本化是可读化的意思,在 GPT4 完全公开后,图像也将成为索引信息,因此这段话的本意还是将更多东西 token 化))
Generative Agents 的知觉设计:关联性难题
区别于接受互联网环境信息的 AutoGPT,Generative Agents 的知觉系统仅在人工赋予 Agent 的有限环境中生效,因此也显得愈发可控。
也正是因为如此,对于场景中可知觉的信息,在 GA 的框架下能得到更有效的管理
[Agent's Summary Description]
Eddy Lin is currently in The Lin family's house: (Eddy Lin's bedroom: desk) that has Mei and John Lin's bedroom, Eddy Lin's bedroom, common room, kitchen, bathroom, and garden.
Eddy Lin knows of the following areas:
The Lin family's house, Johnson Park, Harvey Oak Supply Store, The Willows Market and Pharmacy, Hobbs Cafe, The Rose and Crown Pub.
* Prefer to stay in the current area if the activity can be done there.
Eddy Lin is planning to take a short walk around his workspace. Which area should Eddy Lin go to?
如上述 Prompt 所示,由于 Generative Agents 预定义了空间的树状层级关系,这使得当其作为知觉系统时,可通过对树的层级遍历和自然语言拼装实现知觉系统的有效传达。
同时,基于树状结构,这允许了 Agent 基于自身需求在树上进行深度搜索。
该样例作为补充,讨论了数据结构设计中关联性和结构化的价值。以搜索引擎为例,仅通过关键词关联进行检索的联系是偏弱的,且不能体现层次信息,以及层次信息中蕴含的知识。
对于上面这点,我们举一个简单的例子:
迪娜泽黛是一个因身患魔鳞病深居简出的 Agent,她的家在须弥城,有一天她突发奇想希望能在病逝之前看一看海。她通过搜索引擎关联搜索,并找到了推荐度最高的大海聚香海岸,为此她不远万里来到了沙漠,但差点在路上噶掉。她的好朋友迪希娅追上来给了她梆梆两拳,跟她说你去隔壁奥摩斯港看海她不香吗?
对于绝大部分的信息,我们所需的并不只是信息本身,更包含其中的潜在结构和关联。而对于游戏中的复杂数据更是如此。
这为我们知觉系统设计带来了第二个难题:我们要如何建模我们语境空间中零散的信息?我们要怎么通过最结构化最易读的方式有效对其索引?我们要如何建模并用工程辅助 GPT 的索引过程?
我们依旧简单举几个例子来进行讨论:
- 如果 GPT 能够读取我们的设计文档,它要如何整合多个文档之间的关联?如何构建索引?
- 如果 GPT 要阅读我们的代码库,其要怎么快速跳转并逐层理解模块、功能、接口?
- 如果我们希望 GPT 作为 Agent 来进行游戏,GPT 要如何经过 UI 步骤准确进入系统层级?
由此,除了数据本身的结构化(指高度可读),数据库的结构化(指关联构建)也是为知觉系统服务的一个重要课题。
知觉系统及开发数据环境的构建
该议题显然还只是一个开放性的讨论,知觉系统的设计并不仅仅包括设计智能体依赖什么接口进行知觉,更要求知觉系统与环境的匹配,以及工作目的与环境的匹配。
仅就这方面而言,作为一个方向性的倡议,对知觉系统的开发可能分为以下步骤
数据处理 / 管理
对 办公文件 / 数据 构建通用读取接口
以同类信息为单位,设计通用的字段(由人设计和管理,AI 能力尚不至此)
以程序 API 接口为例:可能包含以下字段
- API 接口名
- API 调用参数
- 所属命名空间
- 所属父类
- API 接口描述
- API 接口描述向量(可能用于语义索引)
- 源文件索引(用于监听和更新)
- 源信息(源文本 or)
- etc...
围绕既定的通用字段,以对象为单位,依靠 GPT 的文本能力自底向上进行总结和编码
- 我们尝试给定规范让 GPT 自动阅读代码段并总结接口,转化为 bson 文件
构建对象索引数据库
- 如储存进 mongoDB
(设计孪生数据的自动更新机制)
知觉系统驱动
基于上述索引数据库,以视图为单位进行访问,并设计 视图 2 Prompt 的转化格式
- 依旧以 API 接口为例,我们将 AutoGPT 的 Command 信息表现为以数据库形式储存
对于如上数据库信息,我们对于以视图为单位进行整理,将其转化为 prompt 输入
'Commands:\n' '1. Google Search: "google", args: "input": "<search>" \n' '2. Browse Website: "browse_website", args: "url": "<url>" , "question": "<what_you_want_to_find_on_website>" \n' '3. Start GPT Agent: "start_agent", args: "name": "<name>" , "task": "<short_task_desc>" , "prompt": "<prompt>" \n' '4. Message GPT Agent: "message_agent", args: "key": "<key>" , "message": "<message>" \n' '5. List GPT Agents: "list_agents", args: \n'
对于对数据库进行感知的任务,我们需要进一步设计 Pormpt 驱动 Agent 的行为
- 对于 Agent 开启的指定任务线程(区分于主线程的感知模块),其起始 Prompt 可能呈这样的形式
如上是你的目标,为了实现这个目标,你可能需要获取一系列的信息,为了帮助你获得信息,我会为你提供一系列的索引访问接口,请你通过如下格式输出语句让我为你返回信息。
注:如果你请求错误,请你阅读返回的报错信息以自我纠正
例:
<通过接口名称检索 ("接口名称")>
<通过接口功能检索 ("访问网页")>
<通过父级名称检索 ("父级名称")>
为 GPT 设计自动化指令解析与执行模块
- 如对上述数据访问接口,仍需匹配一套自动解析访问指令并进行数据库检索,返回指定视图格式转换后的 Prompt(当然也可以是对应视图的 bson 转 json 文件,不使用源数据以过滤系统信息)
可以预见的,基于上述知觉框架,我们能让 Agent 一定程度上在语境中自动化实现基于任务的信息收集。
非工程化的试验样例
(使用了我先前写过的卡牌游戏,基于指定任务让其主动收集信息并编写新的技能脚本)
TBD:号被 OpenAI 噶了,我也很绝望啊
工作记忆:组织 AI 记忆系统
记忆系统的构成其实相较知觉系统等更为抽象,它用于管理 AI 运行时作为背景的长期记忆,以及定义决定了 AI 当前任务及目标的短期记忆。
从某种意义上来说,其极度依赖工程实践中的迭代,因此我现在空手无凭,相比也说不出什么好东西。
但我们依旧能从前人的工作中获得一定的参考。
AutoGPT 的记忆设计:粗放但有效
在 长时记忆(过去)、评估系统(价值)、注意系统(关注)这三个要素中,AutoGPT 做得比较好的无疑只有第一个。
AutoGPT 的核心记忆设计依赖于预包装的 Prompt 本体,这一包装包含如下部分:
Content:用于定义 AI 当前的状态
Goals:用于储存用户定义的 AI 任务
Constraints:用于告诉 AI 约束和部分行为指引
- 让 AI 通过 “thought” 调用长期记忆就是在这里约束好的
- 同时鼓励 AI 把当前的输入尽快存入长期记忆数据库
Commands:用于告诉 AI 其可执行的行为
Resources:告诉 AI 它主要能做什么(没啥用)
Performance Evaluation:用于提醒 AI 自我反思
Response Format:用于确保 AI 输出可解析
而在这个预定义本体信息之上,进一步拼贴了如下要素
- 当前时间戳
- 过去几步行为记录
- 依据 “thought” 从长期记忆数据库中抽取的记忆片段
- 用于驱动执行下一步的 Prompt
如上形式,AutoGPT 的记忆设计相对粗放,其依赖于 GPT 对数据库的写入,并将索引记忆的工作完全交予了基于关联的向量数据库索引。
也正是因为这个,在实际使用中,不乏能遇到 AutoGPT 在运行中发生记忆紊乱,开始重复进行了既往的劳动、或钻牛角尖做些无用功的情景。
但从另一角度,其 “自主将收集到的信息写入记忆” 这一功能作为一个 以完成任务为目标 的 Agent 而言无疑是非常合适的架构设计。
Generative Agents 的记忆设计:精心构建的金字塔
区别于 AutoGPT 主动写入的记忆,Generative Agents 的记忆源自被动的无限感知和记录,因此显得更加没有目的性。也正因如此,其需要一种更妥善的管理形式。
Generative Agent 通过自动化评估记忆的价值,并构建遗忘系统、关注系统等用于精准从自己繁杂的记忆中检索对于当前情景有用的信息。
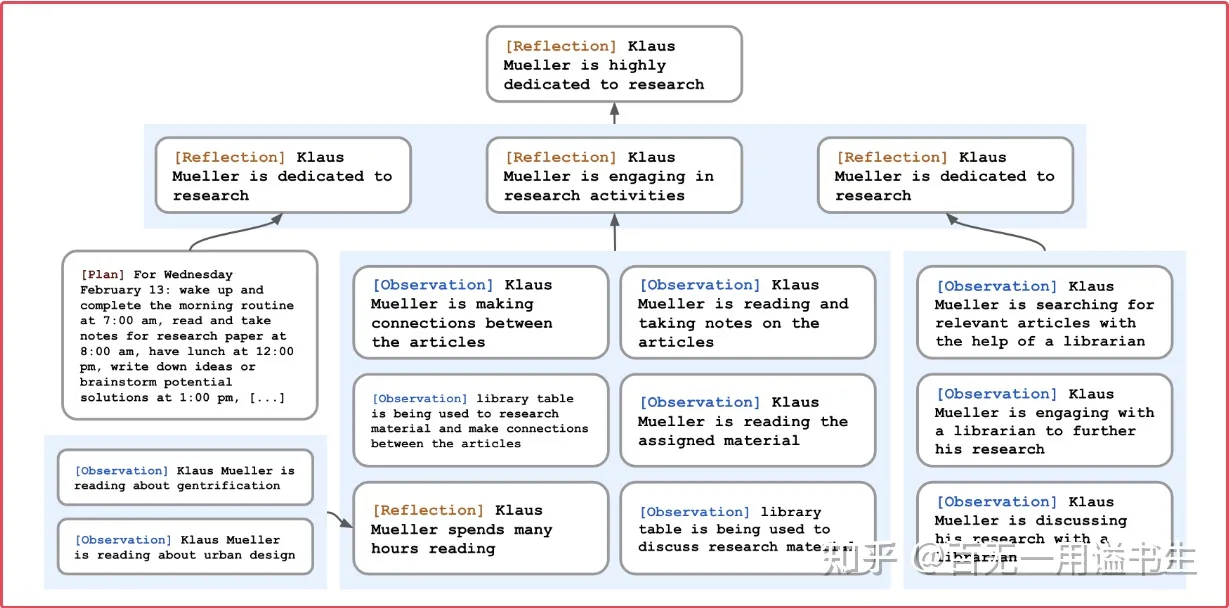
Generative Agents:基于 Reflection 构建记忆金字塔
进一步的,其通过反思机制强化了记忆的价值,使得高层洞察从既有记忆的连结中涌现,这一机制通常被用于将 信息转化为知识,并构建出了有效记忆的金字塔。
而毫无疑问,相关的洞见对于 “完成任务” 而言也是极具价值的。
相关的更有效的记忆管理无疑很快就会被更新的项目学习。
记忆系统的构建讨论(放飞大脑)
但从某种意义上来说,对于一个我们希望其帮助我们工作的智能体而言,像 Generative Agent 这般的巨大数据库也许并未有充分的价值,何况我们所输入的内容原始层级就较高(这一层可能在前面的知觉系统中,就让一定程度上的高层洞见自主产生了),不易于进一步的堆叠。
也许,我们更该关注的是 Agent 对自身短期记忆的管理,即让 Agent 锚定自身的状态,并自主抽象出凝练的短期记忆和关注方向。
在 AutoGPT 的框架下,我们能构建一个专用的短期记忆文本文件,供 GPT 自身编辑,对于每次会话开始时,该文本文件都会自动嵌入 Prompt 中,从而永续保存在 GPT 的上下文窗口内。
该短期记忆主要用于记录当前目标执行进度,以及 GPT 对目标的实际分解形式。
相应的,GPT 的行为记录也能被下放至长期记忆中,构成行为与储存资料的数据对,使得记忆管理更加规范。易于在记忆向量检索时取得期望的效果。
(我本该写得更靠谱一点,但我写到这里已经快累死了,让我开摆罢)
不过显然,这部分设计需要在工程中得到迭代
(可以遇见的,以 AutoGPT 的热度,半个月内就会有人为其设计相应的 mod)
运动系统:让 AI 可及一切
基于知觉系统和记忆系统,已经能构建一个使用语言解决问题的智能体了。但最为关键的改造世界部分则依旧缺席。
虽然这么说也不准确,其实运动系统的部分在知觉系统的讨论中就以提及了:对外界的主动交互并感知,就是一种 “运动”。
我们最终总会不满足于让 AI 帮助我们思考问题,我们想让 AI 帮我们走完最后一步。由此,我们需要让 AI 能与世界进一步地互动。
- 我们大胆假设未来游戏中的 Agent 能通过 API 驱动自身在场景中无拘无束(拼装行为树
- 再大胆假设他们能使用 API 实时把需求的内容转化为发布给玩家的任务(拼装任务节点
- 继续大胆假设,AI 根据我的需求把今天要配的啥比表直接配完,当场下班(笑
(而这一切,都是可能,且近在眼前的)
而这最终又回到了原始的问题 —— 我们能给 AI 什么
AI 能做的一切都基于我们的赋予,包括语言能力,包括思维能力,包括对话能力,更包括前面那些知觉和记忆的能力。运动也无外乎如是,其落实到了两个问题上:
- 如何为 AI 构造充分实用的工具(高度开放的 API 设计
- 如何让 AI 找到足够趁手的工具(易于检索的 API 平台
- 如果让 AI 能够正确地使用工具(高鲁棒的 API 执行器
而这其中,进一步要求让 API 可读和可索引,由此回到我们在知觉系统中的课题,也不必过多赘述了。
在结尾处重新梳理一下本文核心讨论的观点
- 大语言模型的实质是一个拥有智能能力的语言计算器
- 我们不该将其当作独立的智能体看待,但能在其基础上通过构建系统创建智能 Agent
- 为此,我们需要通过信息工程,让 AI 能够真正感知和改造世界,从而改变我们的生产进程
寄予厚望
感谢有人忍受了我阴间的行文和一路跑偏的思路,真能看到这里
红豆泥私密马赛西塔!!!
从某种意义上,本文实际上并没有讨论什么实质性的东西,但作为一个近期思路变化的总结,和对 AI 未来发展的展望,乃至对未来生产力发展的展望。我希望它有一定的参考价值。
可以预见的,AI 对于生产的作用显然并不止于我们上面所讨论的这些,我们不仅希望人要为 AI “赋能”,更希望 AI 能进一步地为人赋能:
- 通过 AI、以及对信息的管理,我们能极大程度上降低复杂团队内部的沟通成本和信息获取成本
- 通过更智能的 AI,能更好地辅助内容创作,让创作者把有限的生产力放在抓住更亮眼的 Sparks 上
- 通过基于 AI 的高度自动化流程,也许我们真的能看到每个人都能将自己的空想所具现化的未来
为 AI 开放一切,为 AI 提供信息,这两个 “为” 才是走向 AIGC 的唯一明路。是让 AI 真正走入生产,解放生产力的唯一正路。
- 作为 AI 研究者,我愿意拭目以待
- 作为游戏开发者,我希望积极地将其运用到我的生产过程中
- 作为团队成员,我期盼生产革命能从我的身边掀起
- 作为马克思主义者,我必将推动着它解放世人们的生产力