AI 绘图大模型 - Stable Diffusion
Author:S4kana | Editor:S4kana
引言
Stable Diffusion,一个听起来让人望而却步的英文词组,通俗来说其实就是我们常说的 AI 绘图。
目前互联网上有相当多有关 Stable Diffusion 的内容,其杰出的效果和简单便捷的操作也是 AI 绘图能如此广泛传播的原因之一。但那些教程更多的侧重于实操,作为未来的专家(专业炼丹师),我觉得我们除了需要对其应用有了解以外,也应该对其中的原理有一定的了解。
SD 简介
稳定扩散(Stable Diffusion)是一个深度学习的文本到图像模型。
于 2022 年发布。是一种潜在扩散模型,一种深度生成神经网络。它的主要功能是根据文本描述生成详细的图像。
要生成图像,用户输入一个文本描述,SD 模型引用与描述中单词相关联的关键词对。然后,模型产生一个与图像中识别出的模式相对应的形状。经过几次传递,图像变得更清晰,最终产生与文本提示匹配的最终图像。
🤔抽象解释
想象一下你有一个魔法沙盘,最初沙盘里全是混乱的沙粒(代表随机噪声)。现在,你想让这些沙粒按照一定的指令排列成一幅美丽的图画。Stable Diffusion 就是这样一个 “魔法师”,但它是在数字世界中工作的,通过算法一步步地将初始的一团数字 “乱麻” 变成一张清晰且有意义的图像。
SD 模型本身其实并不简单,但得益于广大无私奉献的开发者 —— 他们将 SD 模型中的复杂参数和功能实现完全集成在一个简洁的 WebUI,意味着你完全可以在一个浏览器网页中,简单调节几个数字并点击 “确定” 就能生成你想要的图片,让一个完全不懂大模型的人来使用也完全没问题!
🥰开源的力量
后面的学习中你会了解到 “开源精神” 的伟大之处!不仅仅是开发 WebUI 的开发者们,之后你在下载生成图片所需要的模型时会发现,两个资源最丰富的 SD 资源网站 ——Civita 和 HuggingFace,他们甚至不需要你注册账号登录就可以直接获得免费的资源!!这离不开各位开发者们的共同努力!让我们虔诚的跪下来给他们叫声爹吧!
SD 原理
0. 最前面的话
接下来我们通过几个具体步骤来分解 SD 的运作原理,一步步搞懂 SD 究竟是如何生成图片的。你可能完全看不懂下面的分点,不用担心!我会尽可能详细的介绍每一个你看不懂的点,保证你能学到一些东西!
建议参考文档:[稳定扩散(Stable Diffusion)是如何运作的]:https://waytoagi.feishu.cn/wiki/TNIRw7qsViYNVgkPaazcuaVfndc
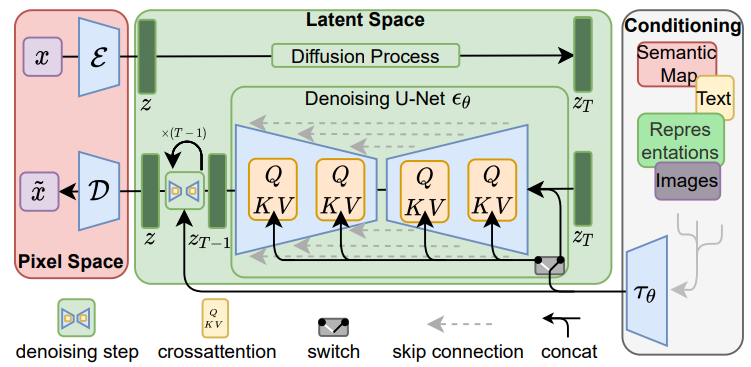
这是原论文给出的 pipeline,如果可以直接看懂就不用往下看了,看不懂的话可以看看下面的内容。
1. 综述
Stable Diffusion(SD)是一种生成模型,用于从噪声图像中生成清晰的图像。它采用了 Diffusion Model 的基本原理,通过逐步去除噪声的方式,将噪声图像转化为清晰图像。SD 框架包括了三个主要组件:
- Text Encoder(文字编码器)
- Generation Model(中间产物)
- Decoder(解码器)
大致框架如下图所示,暂时看不懂没关系,我接下来会为你一一讲解! 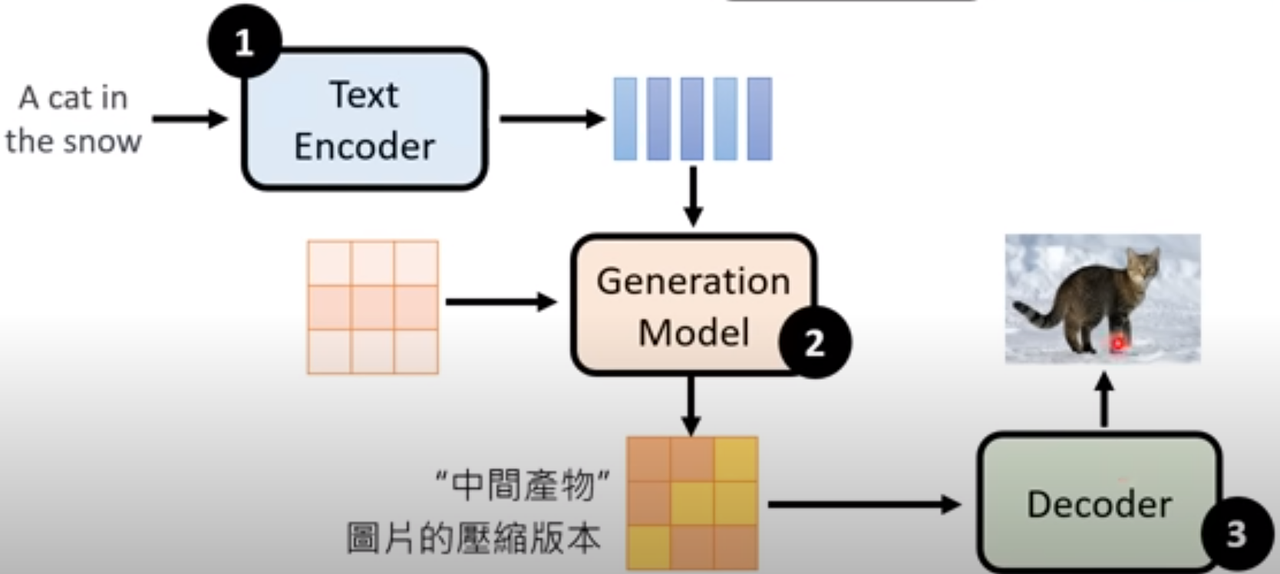
🤔噪声是什么?
噪声可以被描述为图像或信号中不希望出现的额外信息或干扰。想象一下,你正在看一张图片,但突然间图片变得有点模糊或混乱,变成了毫无规则的色块马赛克,这种模糊或混乱的部分就是噪声。(类似于老一代电视的雪花屏)
🤔Diffusion Model 的基本原理是什么?它和 Stable Diffusion 有什么关系吗?
Diffusion Model 的基本原理是一种生成模型,它通过逐步去除噪声来生成清晰的图像。
而 Stable Diffusion(稳定扩散)是对 Diffusion Model 的一种改进和稳定化。它通过引入额外的组件和技术,以确保生成图像的质量和稳定性。市面上还有很多使用 Diffusion Model 或类似模型的,例如 DALL-E,Imagen 等,你们感兴趣可以自己去了解一下哦!
2. 基本逻辑
雕像本来就在石头里,我只是把不想要的部分去掉 —— 米开朗基罗
在详细介绍 Stable Diffusion 各个部分之前,我们先来了解一下 SD 是如何生成出一张我们想要的图片的
事实上,生成一张图片的逻辑远比我们想的要简单!下面是生成一张猫猫图片的过程:
- 首先,模型随机给出一张毫无逻辑的噪点图片
- 然后,模型使用一个叫做 Denoise 的办法,将噪点去除掉一点
- 反复执行 Denoise 过程,直到猫猫出现
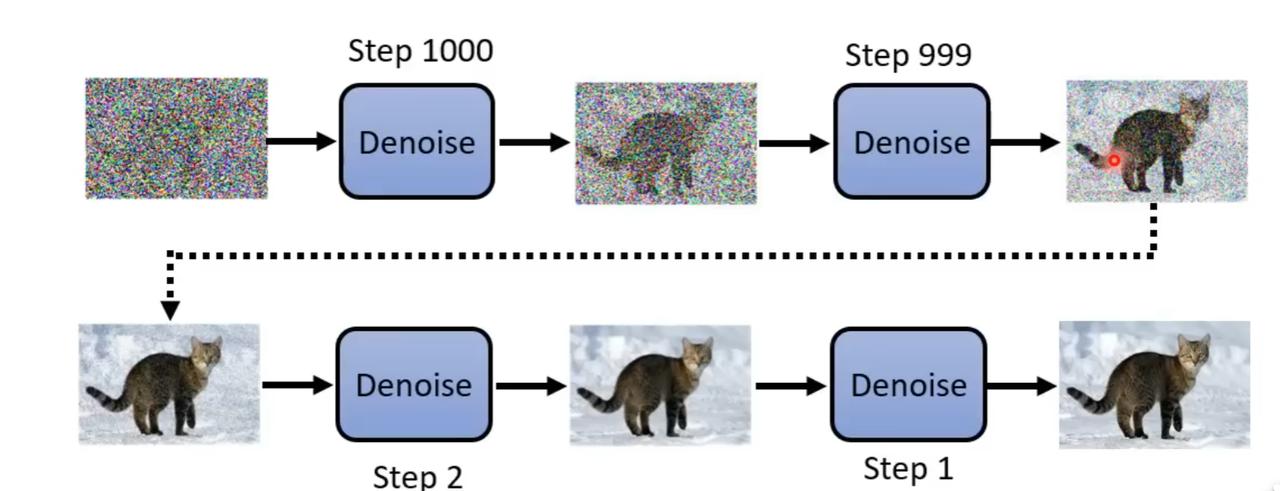
这看起来很不可思议!一张随机生成的噪点图片怎么可能变成一个猫猫呢?其实人也可以做到类似的事情:
- 首先,一位雕塑家在路上随便捡了一块石头
- 然后,雕塑师使用锤子和凿子削去一些他不想要的部分
- 反复执行这个过程,直到雕塑被雕刻出来

所以生成图片的逻辑和大多数人第一时间想的其实并不一样!与其说他在 “创造”,不如说他在 “消除”。
虽然这种消除本身也是在进行创造,但事实是,Stable Diffusion 所做的并不是直接生成一张图片,而是由一张满是噪点的图片一点点演变而来的。
在明白了这些以后,我们就可以继续下面的学习了。
🤔为什么不直接正过来生成一张图片,却用这种看似复杂的减法来生成呢?
事实上,这种看似复杂的减法对于模型来说更加省力!主要反映在以下几点:
- 噪声建模的灵活性: 模型更加适应去除噪声的模式,而这种模型的训练对于人来说也更加方便,毕竟只要在正常的图片里加噪点就可以当作数据集给模型训练了!
- 提高生成图像的质量: 逐步去除噪声的过程可以帮助生成图像更加清晰和高质量。相比直接正过来生成一张图像,这种减法的方法更容易获得清晰度高、细节丰富的图像。
- 对生成模型的要求降低: 由于 Diffusion Model 逐步去除噪声,生成模型不需要一次性生成完整的高质量图像,因此可以使用更简单、更高效的生成模型,降低了模型的复杂度和计算成本。
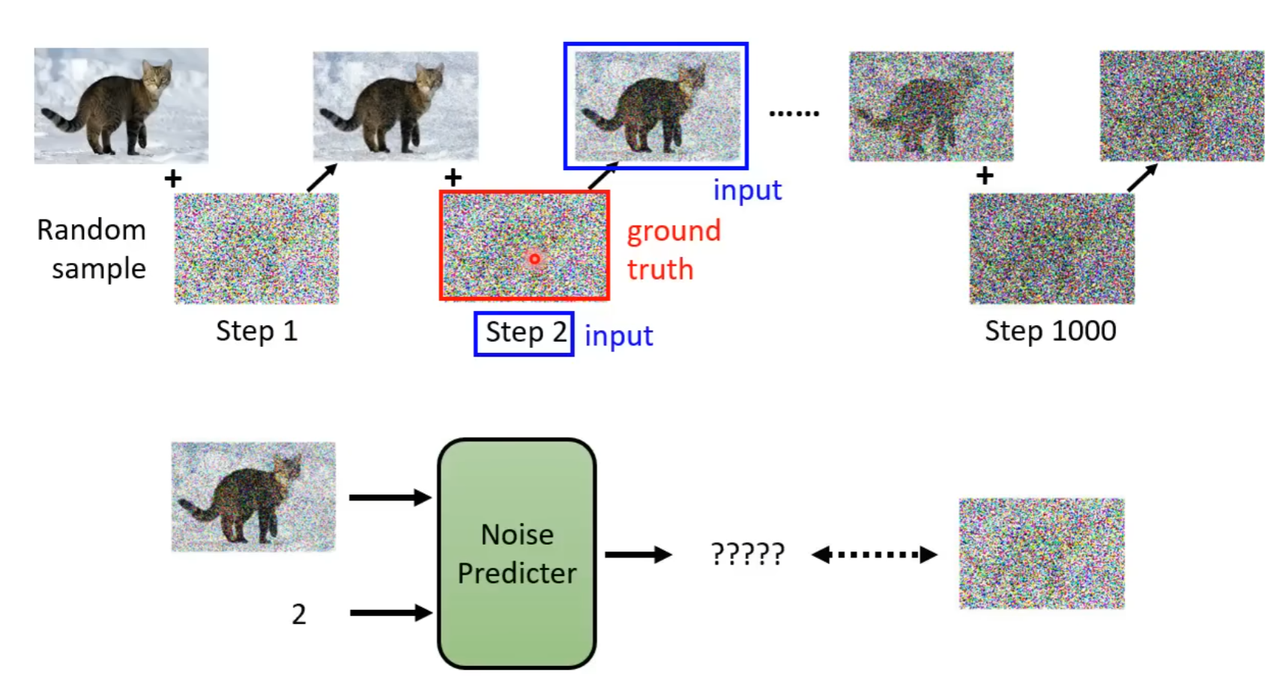
3.Denoise(降噪器)
在 SD 生成图片的基本逻辑中,还有最重要的一个部分没有解释清楚。
Denoise 到底是何方神圣?它是如何做到消除噪点这件事的?
基本逻辑
为了能够实现 “消除” 的功能,Denoise 会做到以下几件事:
- 输入噪点图片和当前步数(消除次数)
- 预测噪点图片中的噪点
- 将原图片减去预测的噪点图片,使图片变得更清晰一点
🤔步数,也就是当前消除次数,对 Denoise 有什么帮助?
步数,其实也可以说是 “被噪点污染程度”,当步数越接近零,图片就会越清晰,噪声也会越来越小。所以 Denoise 会根据步数判断这次 “消除” 是要大刀阔斧还是小心翼翼。
如果步数还很高,就变化的多一点;步数比较低的话,就不会有太大变化了。
- 基本结构
我们来看看 Denoise 的基本构造图: 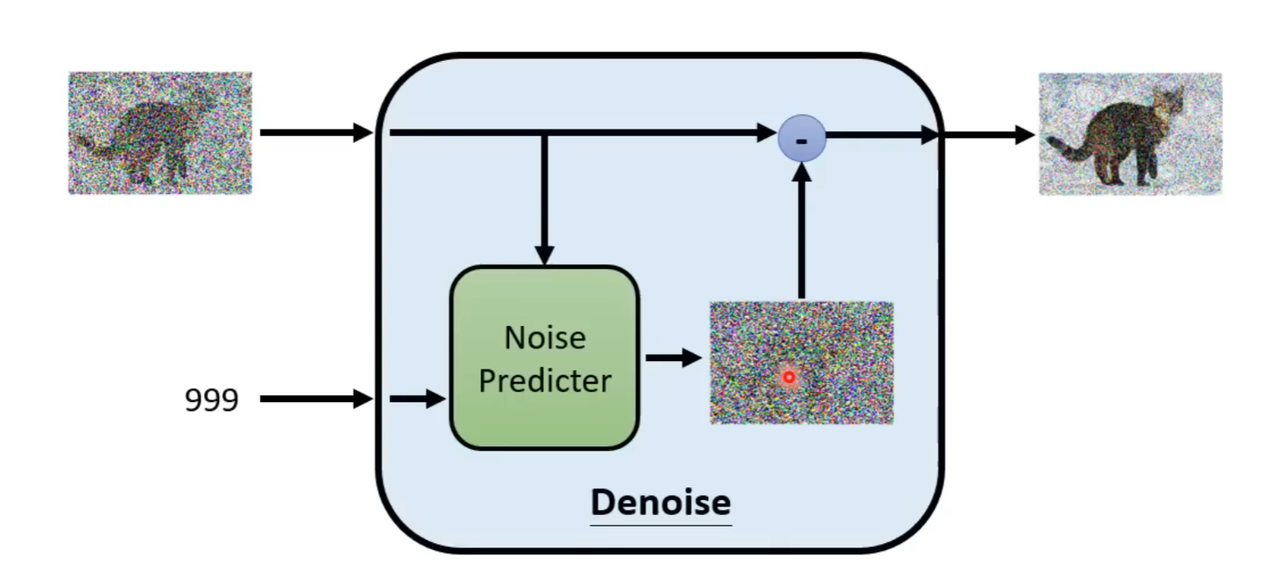
你会发现 Denoise 的内部几乎空空如也!真正重要的部分只有一个 ——Noise Predictor,它的作用就是预测一张带有噪点的图片中的噪点。也就是:
带有噪点的图片(输入)- 预测出的噪点(Predictor) = 少了一些噪点的图片(输出)
🤔为什么不直接生成消除噪点后的图片,而要通过做 “减法” 的方式来一点点消除噪点呢?
其实直接生成消除噪点后的图片,也就是跳过 Predicter 这一步骤,也是可行的。 但是从噪声直接变成一只猫和预测噪点这两者的难度区别相当大,绝大多数模型都选择 “减法”。 仔细想想也是了,既然你都可以直接让噪点变成一只猫了,干嘛不直接画一只猫呢(笑)?
训练过程
现在我们来看看 Noise Predictor 模型到底是怎么被训练出来的
这个过程其实极其简单:
- 获得一张清晰的猫猫图片
- 人工给猫猫图片加上噪点图片,记录当前步数
- 将加上噪点的猫猫图片和当前步数作为输入,噪点图片作为输出,以此为数据集来训练 Noise Predictor。
至此,你已经完全掌握了 Diffusion Model 的基本架构!
4.Text Encoder(文本编码器)
这部分主要是解决文生图中 “文” 的问题
文字编码器,顾名思义是处理用户输入的文字信息的。这个编码器有和 GPT 类似的功效,都可以理解文字的含义,只不过最后输出的东西和 GPT 不太一样。
和大家的想法可能会有一些出入,在 SD 中文本处理似乎是对结果影响最大的!和增加模型训练次数相比,对文字输入的优化更能生成一张好的图片。所以你在下面生成图片时,输入关键词时一定不能太草率!
Text Encoder 大致可以分为以下两个步骤(一个 Optional):
Prompt 输入
用户提供的 Prompt 信息通常以文字形式出现,用于指导图像的生成。
当然,一些多模态的图像生成模型,如 GPT-4,也支持以图片、文件等形式作为 prompt。尽管形式不同,但本质上这些 prompt 都是用于激发模型生成相应的图像内容。
🤔Prompt 是什么?
用户提供一个文本 prompt 作为输入,也就是所谓的关键词或者叫提示词。SD 拥有正向和负向两种提示词类型。这可能是一个关于图像内容的描述,比如 "海边日出"(seaside,sunset)。目前 SD 只支持英文的 prompt,不过也有插件能实现中文到英文的实时转换!不必担心!
Prompt 编码
计算机不能直接理解文字,它需要将文字转换成一种特殊的形式,就像是把文字翻译成一种它能理解的语言一样。在 SD 模型中,这个过程就叫做编码。
Prompt 通过编码,将文本转换为一个张量表示,并传入下一阶段。
🤔张量表示是什么东西?
Encoder 把文字提示转换成张量表示,也就是转换成一种计算机能够理解的形式,这种形式通常是由数字组成的向量,类似于一种特殊的标识符。
VQ 层的处理(Option)
VQ 层处理是 Text Encorder 和 Generate Model 之间很重要的衔接部位,这里稍做讲解,量力而行
想象一下,你有一个魔法工具箱,里面装满了各种颜色的魔法石。每块魔法石都有自己特定的颜色。现在,你想用这些魔法石来装饰一面墙,但你只能选其中几块石头。VQ 层就像是一个帮助你选择最接近你想要颜色的魔法石的工具,且速度很快!
SD 提到的 VQGAN 网络是一种高性能的图片生成模型,由海德堡大学 IWR 研究团队发布。该模型在多种任务上表现出色,能够生成高像素级别的图片。其核心构架中的 VQ 层采用了离散编码模型的特征,这是其关键之处。
编码后的特征向量(向量化后的 prompt)通过 VQ 层进行向量量化,将其映射到一个预先定义的离散 codebook 中。
这个步骤有助于降低数据的维度并捕获重要的语义特征。
🤔太抽象了!讲了这么多,VQ 层在图片生成中到底起到什么作用呢?
VQ 层在图片生成中的两个方面发挥作用,我叫它 “联想” 的功能。
- 在生成过程中,VQ 层会帮助计算机选择与你的描述最匹配的图像元素,比如你想要生成一个 “春天的景色”,VQ 层会去匹配与 “春天” 相关的提示词,例如 “花朵”“绿树”“灿烂的阳光”,创造出一个生机盎然的图片。
- 结果输出时,计算机会输出一张根据你的描述生成的图像,其中 VQ 层所起的作用就体现在了图像的颜色和形状的选择上。
这样,即使只有文字描述,计算机也能生成符合你期望的图像,而 VQ 层帮助确保图像与你的描述尽可能匹配。
5.Generation Model(生成模型):
Generation Model 是 SD 框架中的核心组件,同时也很复杂,我会尽量简单的为你介绍它的功能
Generation Mode,尽管它内部的复杂到爆炸,但功能其实很简单:
- 接收来自 Text Encoder 的文本描述作为输入,然后利用这个输入来生成图像。
它其中包含各种类型的生成模型,如变分自编码器(VAE)、生成对抗网络(GAN)或是 Transformer 模型等。
- 变分自编码器(VAE): VAE 是一种生成模型,旨在从潜在空间中学习数据的概率分布,并生成新的样本。
- 生成对抗网络(GAN): 负责生成与训练数据相似的样本,而判别器则尝试区分生成的样本和真实的训练数据。
- Transformer 模型: 一种基于自注意力机制的神经网络架构,详情见学习路线
🤔既然 Generation Model 本身具备处理文字信息和输出图片的功能,那还要 Text Encoder 和 Decoder 做什么呢?
有必要声明的是,他们虽然具备吃和吐的功能,但吃进去和吐出来的东西都不是给人看的,或者说都处于一个可以称之为中间产物(Latent Representation)的状态!
- Text Encoder
它产生的文字张量表示,会被神经网络转化为潜在表示作为输入进入 Generation Model,以便于模型更好的理解文字的信息
- Decorder
Generation Model 生成的图片,大致上可分为以下两种:
人看的懂的: Decoder 的作用是放大图片,使其更加清晰
人看不懂的: Decoder 的作用是转化图片,使其转变为人能看懂的图片
为什么会出现人看不懂的情况?因为 Generation Model 生成的图片在大多数情况下也是一种潜在表示,而 Decorder 负责解码出具体的图像内容。
总而言之,尽管 Generation Model 本身具备一定的处理文本信息和生成图像的功能,但使用 Text Encoder 和 Decoder 可以使生成过程更具可解释性,也就是让你能看懂!
6.Decoder(解码器)
转换为最终输出的组件
Decoder,负责将生成的图像表示为像素级别的数据,从潜在表示解码出具体的图像内容。
至此,你的图片经过了千辛万苦,终于输出在了你的面前!恭喜你!